## Summary
Fixes preview dummy payments seed data so seeded products and items
match their team-scoped product lines.
## Root Cause
The preview seed configured `workspace` and `add_ons` product lines with
`customerType: "team"`, but the products inside those lines (`starter`,
`growth`, and `regression-addon`) were configured as `customerType:
"user"`. Environment override writes validate against the rendered
branch config, so unrelated environment updates could fail with a
product/product-line customer type warning.
## Changes
- Mark preview dummy payments products and included items as
team-scoped.
- Export the dummy payments setup helper for focused validation.
- Add a regression test that validates the generated branch payments
override has no config override errors or incomplete config warnings.
## Validation
Passed in the original checkout with dependencies installed:
- `STACK_SKIP_TEMPLATE_GENERATION=true pnpm exec vitest run --config
vitest.config.ts src/lib/seed-dummy-data.test.ts --reporter=verbose
--maxWorkers=1 --minWorkers=1`
- `pnpm -C apps/backend lint src/lib/seed-dummy-data.ts
src/lib/seed-dummy-data.test.ts`
- `pnpm -C apps/backend typecheck`
The temporary clean worktree used for this PR did not have
`node_modules`, so dependency-backed commands were not rerun there.
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
* **Improvements**
* Strengthened payment product configuration with tighter typing and
validation
* Normalized product customer types (switched relevant dummy data from
user to team) for consistency
* **Tests**
* Added tests validating dummy payments configuration and
branch/override validation
* **Documentation**
* Added Q&A documenting a configuration validation failure mode and
required consistency for dummy payments data
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
## Summary
- Move the `/api/internal/[transport]` MCP route from the docs app to
the backend, so the public `ask_stack_auth` MCP tool is served from the
same origin as the AI query API it proxies to.
- Replace the bespoke docs-tools HTTP client in
`apps/backend/src/lib/ai/tools/docs.ts` with an `@ai-sdk/mcp` client
that talks to Mintlify's generated MCP server. The backend AI agent now
consumes Mintlify's lower-level search/fetch tools directly instead of
going through the docs app.
- Swap `STACK_DOCS_INTERNAL_BASE_URL` for `STACK_MINTLIFY_MCP_URL`
(defaults to the Mintlify-hosted MCP URL).
- Move the `@vercel/mcp-adapter` dependency from `docs` to
`apps/backend`.
## Test plan
- [ ] `pnpm typecheck`
- [ ] `pnpm lint`
- [ ] e2e: new
`apps/e2e/tests/backend/endpoints/api/v1/internal/mcp.test.ts` covers
`tools/list` and validation on `tools/call`
- [ ] Manual: hit `POST /api/internal/mcp` on the backend and confirm
`ask_stack_auth` is listed and callable
- [ ] Manual: confirm backend AI agent docs tools resolve via the
Mintlify MCP URL
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
* **New Features**
* Backend docs tooling now uses a Mintlify MCP server for documentation
tools and discovery.
* **Chores**
* Development environment variables updated to point to the Mintlify MCP
endpoint.
* Backend dependency added to support MCP integration; docs package
dependency removed.
* **Tests**
* Added end-to-end tests for the internal MCP endpoint and tool
validation.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
# Shareable Session Replay Links
Adds the ability to share individual session replays via unique, direct
URLs.
https://www.loom.com/share/1e3298a19b114fc38af4bc43dcd5ec48
## What changed
- New admin endpoint — GET /api/v1/internal/session-replays/:id
- Fetches a single session replay by ID with user metadata (display
name, primary email) and chunk/event counts
- Returns 404 if the replay doesn't exist
- Admin-only access, consistent with the existing list endpoint
## New standalone replay page —
/projects/:projectId/analytics/replays/:replayId
- Thin server page wrapper that passes the replay ID to the existing
PageClient
- PageClient detects standalone mode via initialReplayId prop and
fetches replay metadata directly instead of loading the full session
list
- Sidebar is hidden; the replay viewer takes the full width
- "Back to all replays" link shown under the page title
## Copy link button
- Moved from per-session sidebar items to the replay viewer header (next
to the settings gear)
- Copies a direct URL to the currently selected replay
## SDK plumbing
- AdminGetSessionReplayResponse type in stack-shared
- getSessionReplay() on StackAdminInterface, StackAdminApp interface,
and _StackAdminAppImplIncomplete
## Tests
- Happy path: fetch single replay by ID with inline snapshot
- 404 for nonexistent replay ID
- 401 for non-admin access (client and server)
## Test plan
- [ ] Open /analytics/replays, select a replay, click the link icon in
the header — verify URL is copied to clipboard
- [ ] Paste that URL in a new tab — verify the standalone replay page
loads and plays the correct replay
- [ ] Verify "Back to all replays" link navigates back to the list page
- [ ] Verify the original /analytics/replays list page still works as
before (selecting, filtering, pagination)
- [ ] Run pnpm test run session-replays
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
* **New Features**
* Backend: internal endpoint to fetch a single session replay with user
info, millisecond timestamps, and chunk/event counts.
* Admin SDK/App: added response type and admin method to retrieve a
single session replay; admin app maps response into the app model.
* Dashboard: standalone session-replay page, UI adjustments for
standalone mode, and a “copy replay link” button.
* **Tests**
* Added end-to-end tests for retrieval, not-found, and access-control
scenarios.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
DB migration compat / Back-compat — Current branch migrations with ${{ needs.check-migrations-changed.outputs.base_branch }} branch code (push) Has been cancelled
DB migration compat / Forward-compat — Current branch code with ${{ needs.check-migrations-changed.outputs.base_branch }} branch migrations (push) Has been cancelled
DB migration compat / Back-compat — Current branch migrations with ${{ needs.check-migrations-changed.outputs.base_branch }} branch code (push) Has been cancelled
DB migration compat / Forward-compat — Current branch code with ${{ needs.check-migrations-changed.outputs.base_branch }} branch migrations (push) Has been cancelled
## Summary
Rewrites the **Email Server** section of the project email settings page
and the managed-domain setup flow. Replaces the dropdown +
conditional-fields layout with a visual four-card picker, a clearer
unsaved-state model, a stepper dialog for managed-domain onboarding, and
a consistent tracked-domains list. Also fixes two data-correctness bugs
in the managed-domain backend.
## Walkthrough (2×, dead-frames trimmed)
## Before
The saved state was a minimal dropdown, but choosing Custom SMTP /
Resend revealed a long conditional form with a hidden gear toggle for
server config, no clear "what is saved" signal, and a separate dialog
pattern for managed domains.
| Saved (Managed) | Custom SMTP selected |
|---|---|
|
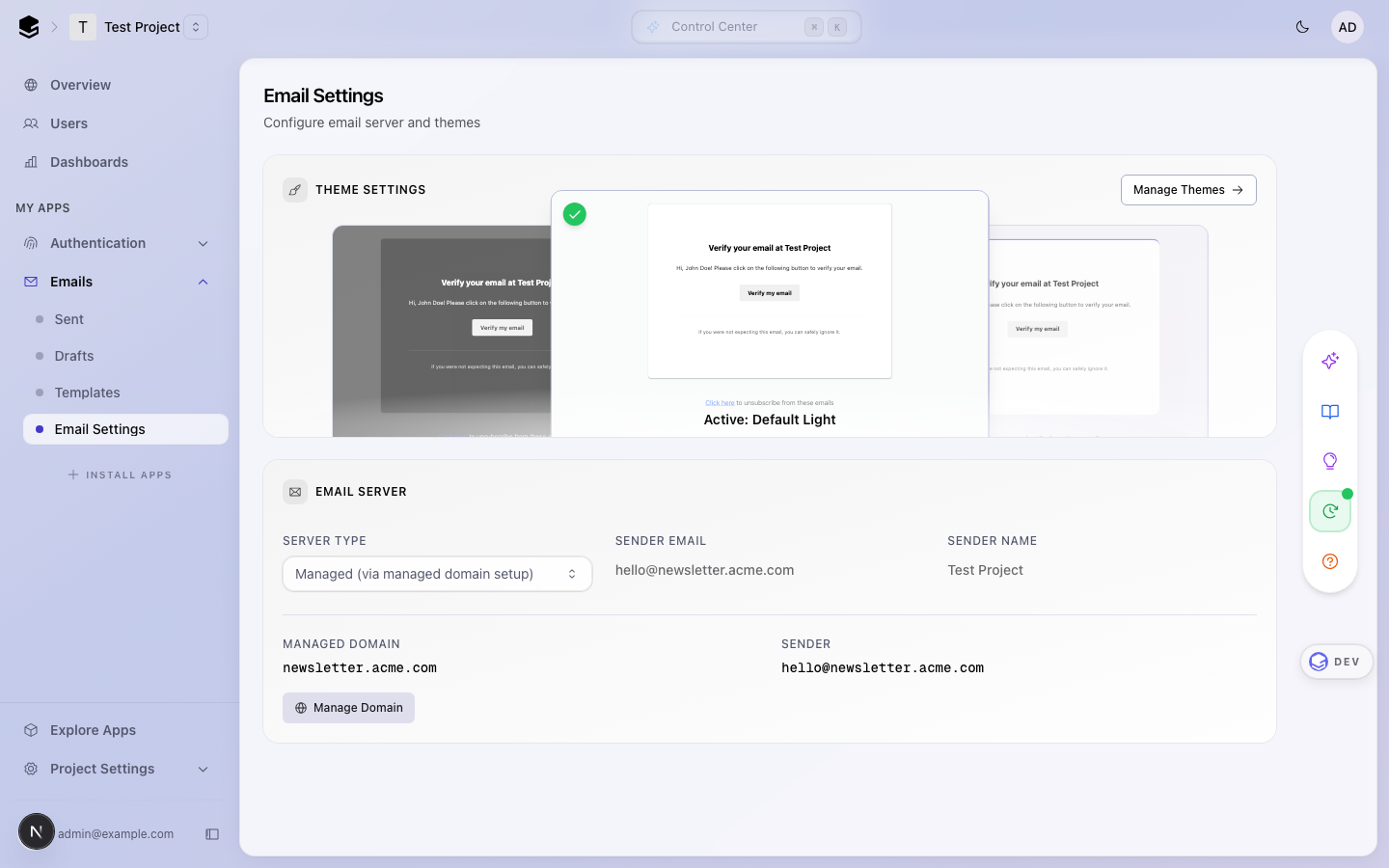
|
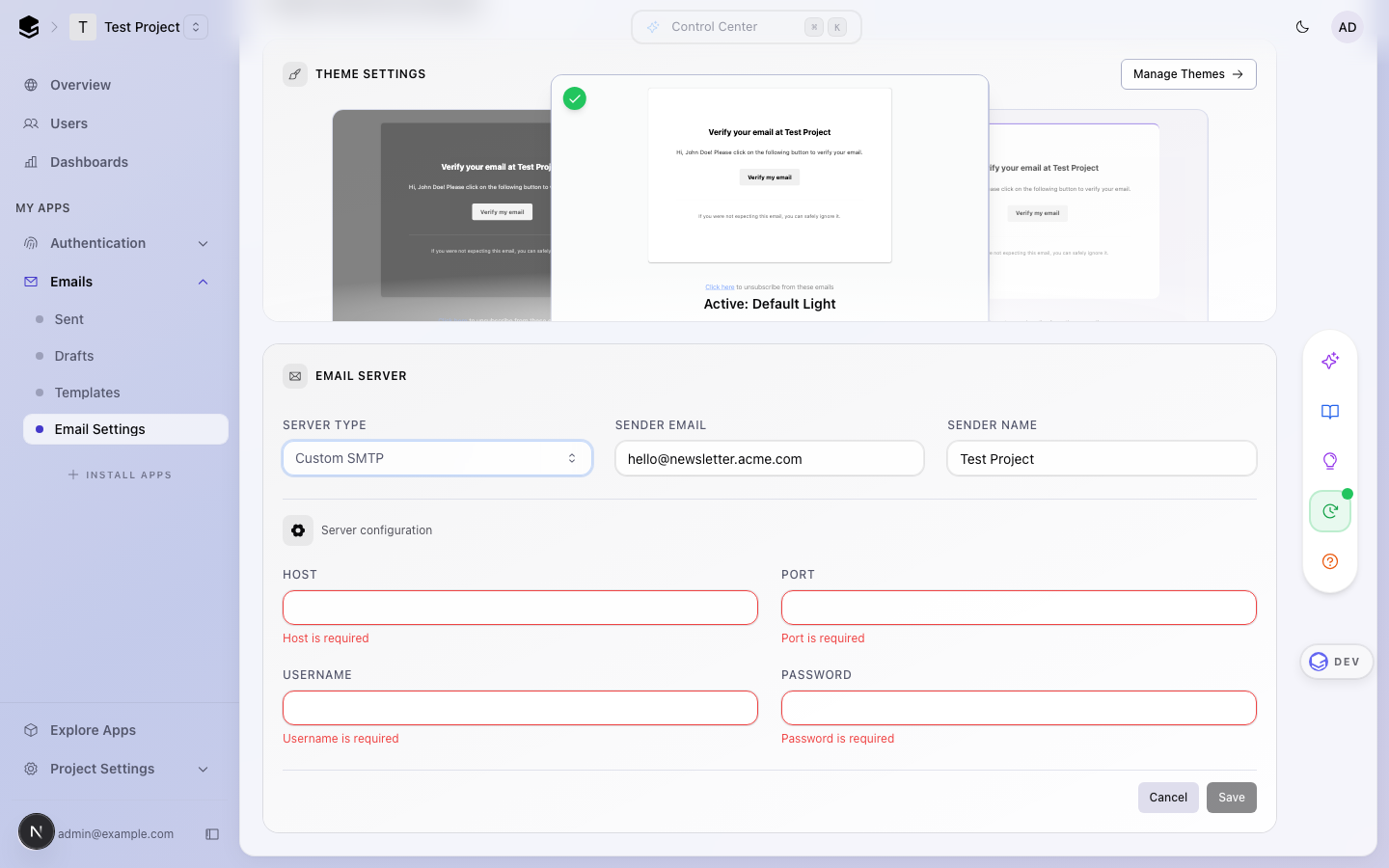
|
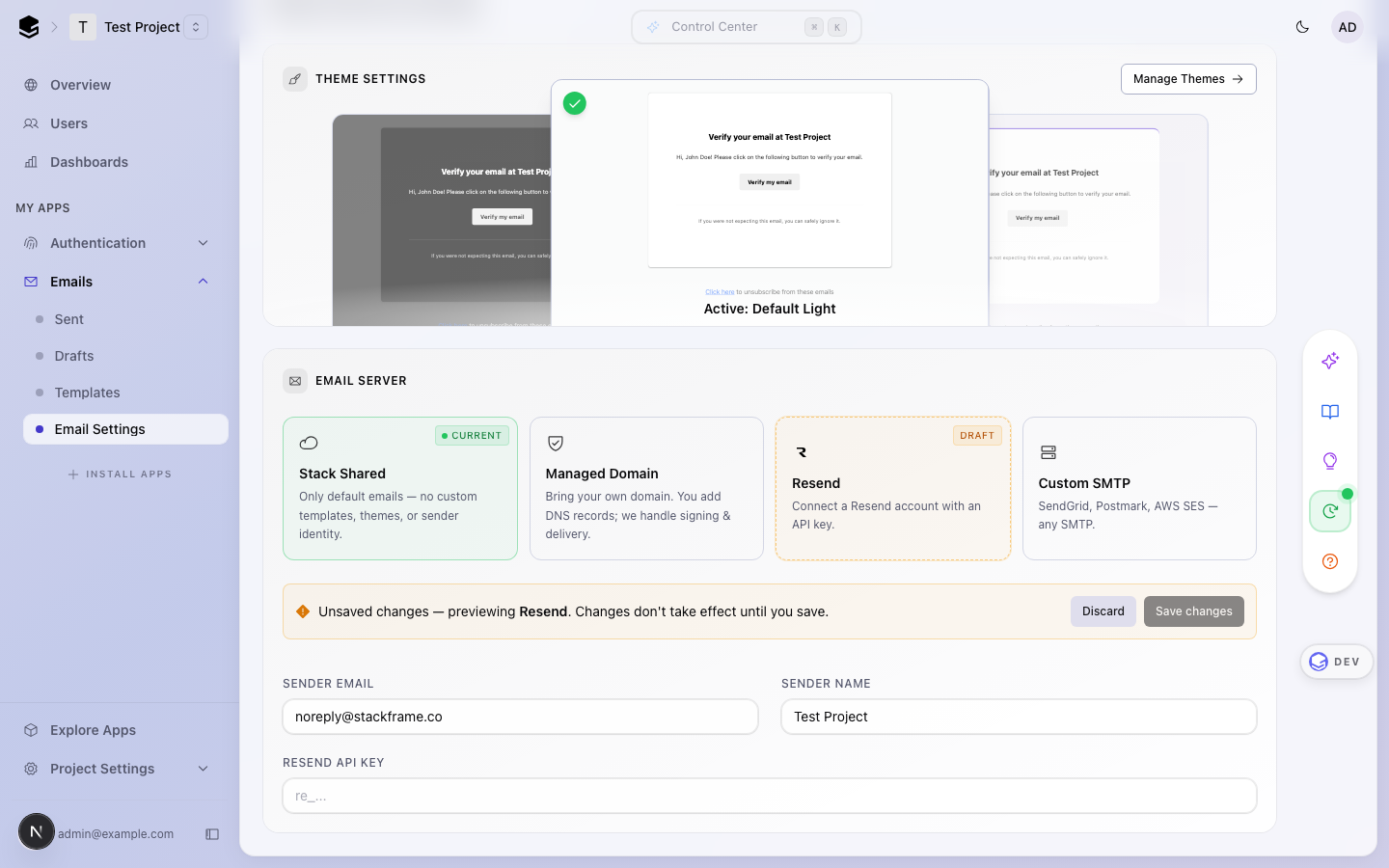
## After — Provider cards
Four visual cards (Stack Shared, Managed Domain, Resend, Custom SMTP)
with updated copy. The saved provider shows a green **Current** pill;
the card the user is previewing shows an amber dashed **Draft** pill. An
amber unsaved-changes banner appears between the picker and the form
when state diverges from saved, so it is unambiguous that a click is not
yet committed.
| Saved state | Previewing a different provider |
|---|---|
|
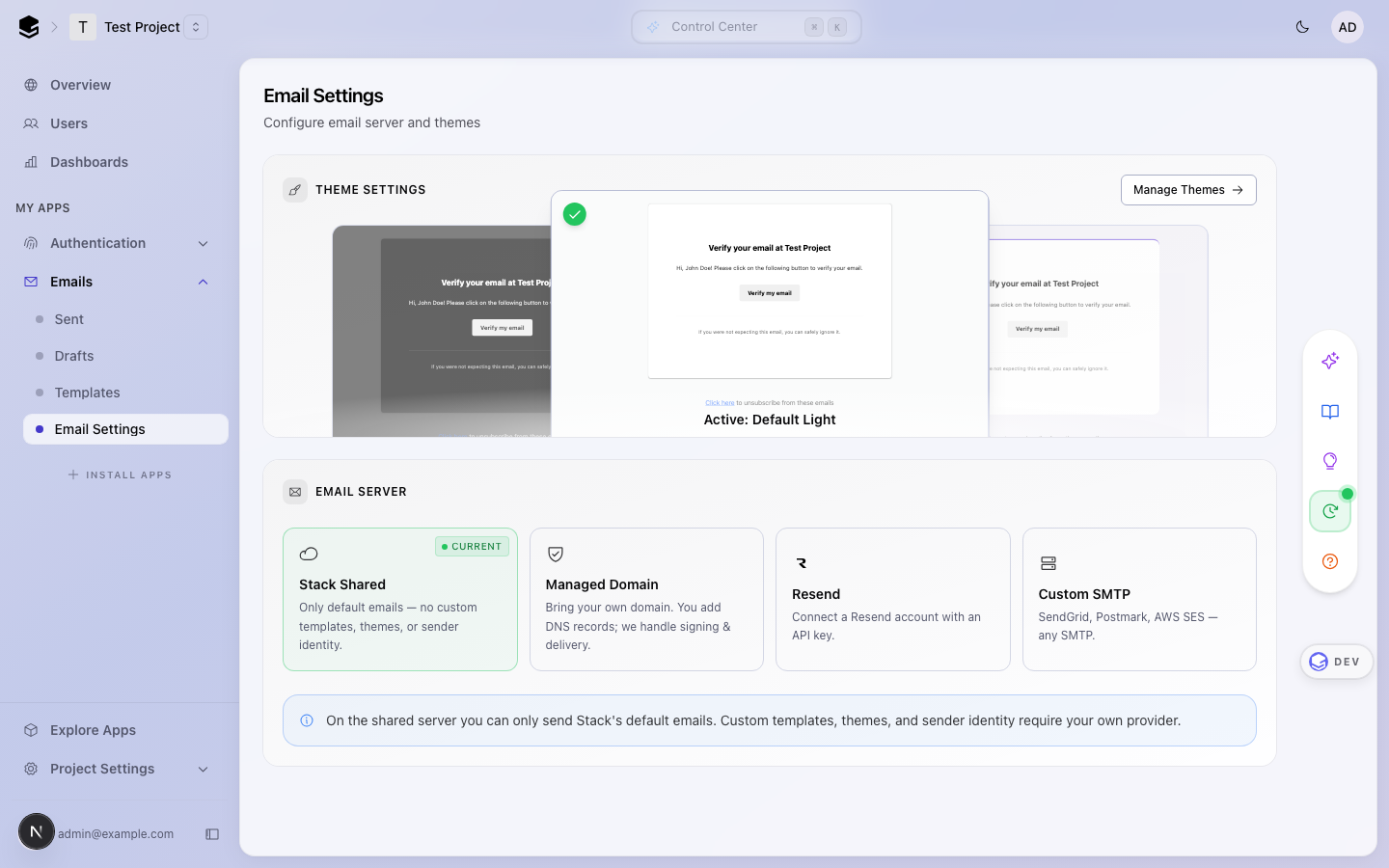
|
|
Copy changes:
- **Stack Shared** — "Only default emails — no custom templates, themes,
or sender identity." (was: "Shared (noreply@stackframe.co)")
- **Managed Domain** — "Bring your own domain. You add DNS records; we
handle signing & delivery." (was: "Managed (via managed domain setup)")
- **Resend** uses the official Resend brand mark (light/dark variants in
`apps/dashboard/public/assets/`)
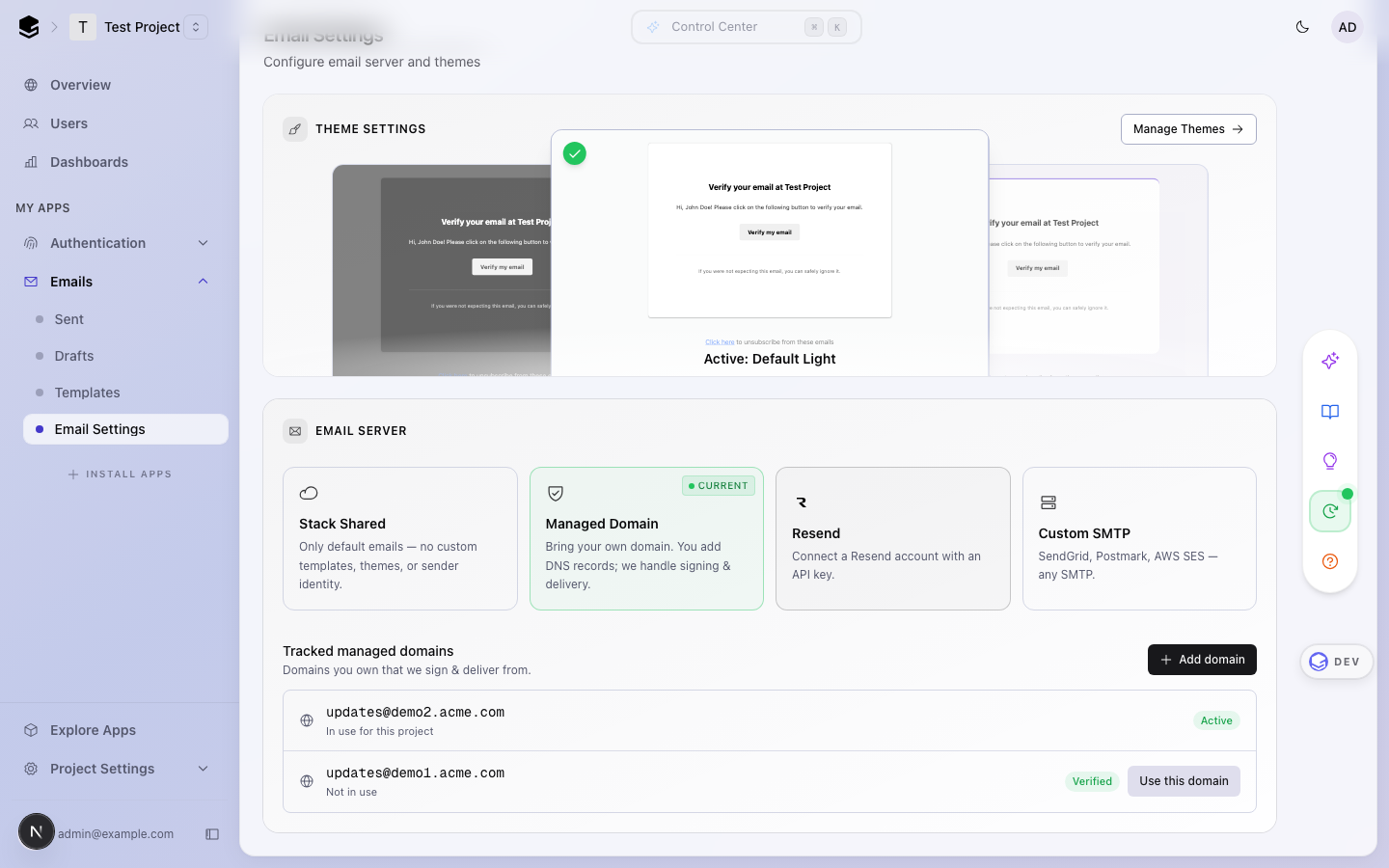
## After — Managed domain list + stepper dialog
Selecting **Managed Domain** immediately shows the tracked-domain list
with an **Add domain** button. Each row reflects real status (Active /
Verified / Waiting for DNS / Verifying / Failed). Exactly one domain can
be **Active** — the one matching the saved email config; every other
verified/applied domain shows a **Use this domain** button so switching
is always possible.
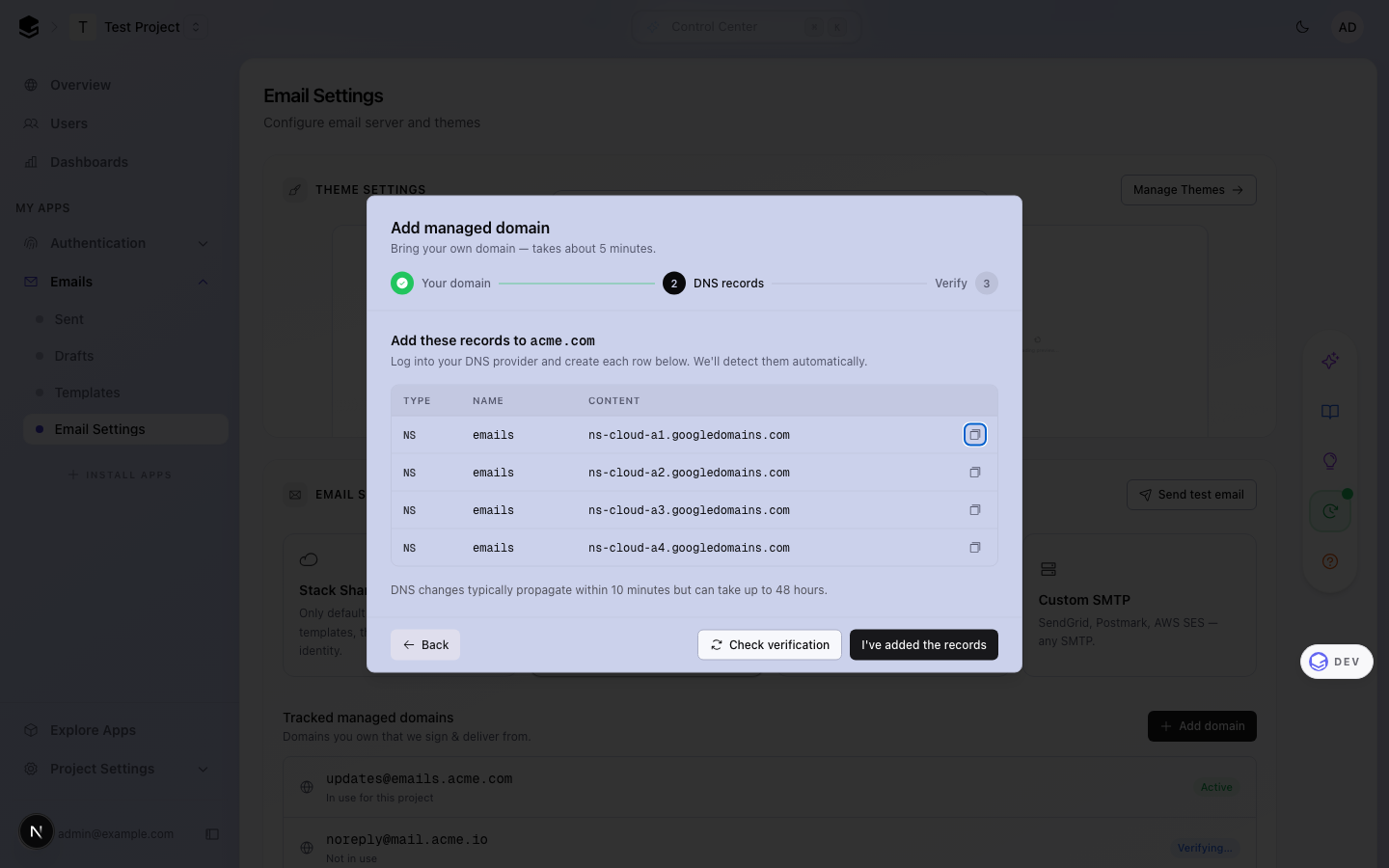
Adding a domain opens a 3-stage dialog with a horizontal stepper (Verify
is right-aligned for the final step). Stage 2 replaces the old bare
NS-list with a proper **Type / Name / Content** DNS records table with
per-row copy buttons.
| Tracked domains list | DNS records table |
|---|---|
|
|
|
## Bug fixes
- **Backend: applying a managed domain did not demote previously-applied
ones.** Multiple rows could end up with status `APPLIED` even though
only one could be in the saved config. New helper
`demoteOtherAppliedManagedEmailDomains({ tenancyId, keepId })` runs
inside `applyManagedEmailProvider` to demote all other applied rows in
the tenancy back to `VERIFIED` before marking the new one.
- **Frontend: "Use this domain" only appeared for `status ===
verified`.** A domain that had been applied then replaced could never be
re-applied from the UI. Button now appears for any `verified` or
`applied` row that is not currently in use; the **Active** label is
derived from config match instead of DB status.
- **Dev mock onboarding now mirrors production timing.**
`shouldUseMockManagedEmailOnboarding()` used to insert domains as
`verified` synchronously. Now the domain is created as
`pending_verification`, and a fire-and-forget `runAsynchronously(() =>
wait(1000))` updates it to `verified` — mirroring the real Resend
webhook flow so the UI states (pending → verifying → verified) are
exercised in local dev.
## Test plan
- [ ] Cards: clicking each card shows `Draft` pill + amber banner;
Discard restores; Save commits and flips `Current` to the new card
- [ ] Managed: Add domain → stage 1 input → stage 2 DNS table + copy →
Check verification flips to stage 3 → Use this domain sets it Active and
demotes the previously-active domain in the list
- [ ] Managed: clicking **Use this domain** on a non-active verified row
makes it Active and the previously-active row back to Verified
- [ ] Shared / Resend / SMTP: existing save + test-email flows still
work (logic preserved verbatim)
- [ ] `pnpm typecheck` (dashboard + backend) and `pnpm lint` pass
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
* **New Features**
* Redesigned email domain setup flow with multi-step verification dialog
* Added copy-to-clipboard for DNS records
* Enhanced provider selection interface with improved visual
presentation
* Onboarding now shows initial "pending verification" state and
completes verification asynchronously
* **Bug Fixes**
* Ensures only one managed domain becomes active when applying a domain
* Improved error handling for email configuration saves
* **Tests**
* Updated end-to-end tests to reflect async verification timing
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
## Summary
- Add ClickHouse error code `386` (`NO_COMMON_TYPE`) to
`UNSAFE_CLICKHOUSE_ERROR_CODES` in
`apps/backend/src/lib/clickhouse-errors.ts`. This stops the Sentry
`StackAssertionError` (`Unknown Clickhouse error: code 386 not in safe
or unsafe codes`) that was firing whenever an admin wrote a query like
`SELECT [1, 'a']` or `SELECT if(1, 'a', 1)`, while keeping the raw error
message out of prod responses.
- Add two e2e regression tests: one against the cross-project
`analytics_internal.users` table, and one against `system.query_log`, to
pin that 386 is wrapped with the generic `Error during execution of this
query.` message in prod (full detail only surfaces in dev/test).
## Why unsafe, not safe
Both callers of `getSafeClickhouseErrorMessage`
(`apps/backend/src/app/api/latest/internal/analytics/query/route.ts:59`
and `apps/backend/src/lib/ai/tools/sql-query.ts:80`) execute
caller-authored SQL under `readonly: "1"` with
`SQL_project_id`/`SQL_branch_id` scoping. The ClickHouse client runs
under a `limited_user` whose grants restrict most tables — but
ClickHouse resolves types **before** enforcing ACL. That means a query
like `SELECT if(1, query, 1) FROM system.query_log` surfaces code 386
with a message like `There is no supertype for types String, UInt8 ...`,
leaking that `system.query_log.query` is a `String` — schema info from a
table the caller can't actually read.
This is the same type-before-ACL class as code 43
(`ILLEGAL_TYPE_OF_ARGUMENT`), which is already classified unsafe.
Classifying 386 as unsafe keeps the defense-in-depth consistent: if
per-customer tables are ever introduced and grants don't block
reference-resolution in time, 386 won't leak their schema.
Cost: in prod, an admin writing a malformed type-mismatch query sees
only `Error during execution of this query.` instead of the supertype
hint. Dev and test environments still show the full error via the
existing `getNodeEnvironment()` branch, so local iteration is
unaffected.
## Test plan
- [x] `pnpm test run
apps/e2e/tests/backend/endpoints/api/v1/analytics-query.test.ts` — all
64 tests pass, including the two 386 regression tests.
- [ ] Monitor Sentry after deploy to confirm the
`unknown-clickhouse-error-for-query` events for code 386 stop firing.
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
* **Bug Fixes**
* Improved handling of a ClickHouse type-mismatch error to prevent
exposure of sensitive data and ensure sanitized error responses.
* **Tests**
* Added regression tests that verify error responses are sanitized,
return consistent error codes, and include expected headers without
leaking internal details.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
## Summary
- Fixes Sentry
[STACK-BACKEND-146](https://stackframe-pw.sentry.io/issues/7377768662/):
`PrismaClientKnownRequestError` P2025 on
`projectUserRefreshToken.update()` during token refresh.
- Root cause: `generateAccessTokenFromRefreshTokenIfValid`
(`apps/backend/src/lib/tokens.tsx`) reads the refresh-token row
upstream, then issues `.update(...)` on it (and on `projectUser`) inside
a `Promise.all`. If a concurrent sign-out (`DELETE
/auth/sessions/current`), session revoke, password change, or user
deletion removes the row between the read and the update, Prisma throws
P2025 and the refresh endpoint 500s.
## Changes
- `apps/backend/src/lib/tokens.tsx` — swap the two `.update(...)`s for
`.updateMany(...)` so a missing row is a no-op, then re-check the
refresh token still exists; return `null` if it doesn't. The refresh
route already maps `null` -> `KnownErrors.RefreshTokenNotFoundOrExpired`
(401), which is the correct user-facing behavior for a just-revoked
session.
- `apps/backend/src/oauth/model.tsx` — in `generateAccessToken`, replace
the "ultra-rare race condition" `throwErr` fallback with `throw new
KnownErrors.RefreshTokenNotFoundOrExpired()` so concurrent sign-out
during an OAuth `refresh_token` grant returns a clean 401 instead of
500.
-
`apps/e2e/tests/backend/endpoints/api/v1/auth/sessions/current/refresh-race.test.ts`
— new regression test that fires `POST /auth/sessions/current/refresh`
and `DELETE /auth/sessions/current` concurrently with the same refresh
token. Before the fix it 500s on the first iteration; after, it passes
in ~12s.
## Test plan
- [x] New regression test passes locally.
- [x] Existing `auth/sessions/**` + `auth/oauth/token.test.ts` still
pass (27 tests, 3 todo, 0 failed).
- [ ] CI green.
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
* **Bug Fixes**
* Refresh flows now detect a revoked or removed refresh token during
concurrent operations and stop cleanly, preventing issuance of an access
token from stale data.
* A specific refresh-token-not-found/expired error is returned instead
of a generic failure when refresh cannot proceed.
* **Tests**
* Added E2E tests exercising concurrent refresh vs sign-out to prevent
race-condition crashes and validate safe handling of competing requests.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
## Summary
Email outbox rows can get stuck in `SENDING` if a worker dies after
setting `startedSendingAt` but before finishing or unclaiming. This
change adds `recoverEmailsStuckInSending`, which runs each email queue
step and marks rows past the stuck timeout as **terminal server errors**
with delivery status unknown, **without** scheduling an automatic retry
(to avoid duplicate sends if the provider already accepted the message).
## Changes
- **`recoverEmailsStuckInSending`**: updates stuck rows with
`finishedSendingAt`, `canHaveDeliveryInfo: false`, and server error
fields; emits Sentry via `captureError` when any rows are recovered.
- **Tests**: `email-queue-step.test.tsx` covers recovery of old
`startedSendingAt`, no-op for recent sends, and idempotency (second pass
does not re-queue).
## Test plan
- [ ] `pnpm` / vitest for
`apps/backend/src/lib/email-queue-step.test.tsx` (requires dev DB like
other integration tests in this package)
Made with [Cursor](https://cursor.com)
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
* **Bug Fixes**
* Email reliability: messages that remained stuck in sending are now
automatically marked as terminal failures, assigned standardized error
details, cleared from retry scheduling, prevented from receiving
delivery info, and recovery emits an alert only when actual work occurs.
Recovery is safe to run repeatedly (idempotent).
* **Tests**
* Added integration tests validating recovery behavior, proper field
updates, and idempotency.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
DB migration compat / Back-compat — Current branch migrations with ${{ needs.check-migrations-changed.outputs.base_branch }} branch code (push) Has been cancelled
DB migration compat / Forward-compat — Current branch code with ${{ needs.check-migrations-changed.outputs.base_branch }} branch migrations (push) Has been cancelled
This PR introduces a context chip bar for the AI dashboard chat panel —
users can click widgets in the sandbox iframe, trigger "Add a
component", or auto-capture runtime errors as chips that are prepended
to the next AI request. It also adds a patchDashboard tool for surgical
find-and-replace edits alongside the existing updateDashboard, streaming
dashboard generation, and an improved system prompt with hook-ordering
guidance for generated components.
DB migration compat / Back-compat — Current branch migrations with ${{ needs.check-migrations-changed.outputs.base_branch }} branch code (push) Has been cancelled
DB migration compat / Forward-compat — Current branch code with ${{ needs.check-migrations-changed.outputs.base_branch }} branch migrations (push) Has been cancelled
<!--
Make sure you've read the CONTRIBUTING.md guidelines:
https://github.com/stack-auth/stack-auth/blob/dev/CONTRIBUTING.md
-->
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
* **Bug Fixes**
* OAuth flows now consistently block extra scopes and access tokens for
shared OAuth keys, enforcing restrictions earlier in the request
processing and across all environments.
* **Tests**
* Added end-to-end regression tests to verify requests with extra scopes
against shared OAuth providers return a 400 response indicating extra
scopes/access tokens are not allowed.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
## Summary
`stack emulator start` now resumes a fully-warm VM snapshot instead of
cold-booting, bringing startup from 30–120s down to ~5–8s with
per-install secret rotation, or ~2.5s with rotation opt-out. The
snapshot is captured **locally on first `stack emulator pull`**, not
shipped from CI — QEMU migration state isn't portable across
accelerators (KVM/HVF/TCG) or `-cpu max` feature sets, so a CI-captured
snapshot couldn't resume reliably on arbitrary user hardware.
Also bundles a pile of CLI QoL fixes (progress bars, PR/run artifact
pulls, PR-build download, native-TS ISO writer replacing
`hdiutil`/`mkisofs`/`genisoimage` host dep, unit tests).
| Scenario | Before | After |
|---|---|---|
| Cold boot (no snapshot) | 30–120s | same, works as fallback |
| `stack emulator pull` (one-time, includes local snapshot capture) |
~30s download | ~30s download + ~1–3 min cold-boot capture |
| Snapshot resume, normal start | — | **~5–8s** |
| Snapshot resume, `EMULATOR_NO_ROTATION=1` | — | **~2.5s** |
Backend (`/health?db=1`) and dashboard (`/handler/sign-in`) return 200
on all paths. Two successive snapshot resumes produce different rotated
PCK/SSK/SAK/CRON_SECRET values per install.
## How it works
**Build (CI)** — `docker/local-emulator/qemu/build-image.sh`:
1. Cloud-init provisioning runs to completion (migrations, seed,
slim-image) producing `stack-emulator-<arch>.qcow2`.
2. Image is built with a topology compatible with later snapshot capture
(pinned SMP=4, phantom seed/bundle ISOs, STACKCFG runtime ISO mounted at
build time, qemu-guest-agent running, placeholder hex secrets baked in
under `STACK_EMULATOR_BUILD_SNAPSHOT=1`).
3. CI publishes **only the qcow2** — no `.savevm.zst` ships.
**Pull (user's machine)** —
`packages/stack-cli/src/commands/emulator.ts` + `run-emulator.sh
capture`:
1. `stack emulator pull` downloads the qcow2 with a progress bar (or
from a PR / workflow run via `--pr` / `--run`).
2. CLI invokes `run-emulator.sh capture`: cold-boots the qcow2 with a
matching device layout (phantom ISOs, fsdev, pcie-root-port, virtfs
detached — migration-incompatible), waits for backend+dashboard health,
then drives QMP: `stop` → set `mapped-ram` + `multifd` caps → `migrate
file:state.raw` → poll `query-migrate` → `quit`. Raw mapped-ram file is
zstd-compressed to `stack-emulator-<arch>.savevm.zst` in the images dir.
3. `--skip-snapshot` opts out (first `start` will then cold-boot).
**Runtime** — `run-emulator.sh start`:
1. Launch QEMU with `-incoming defer` when a `.savevm.zst` is present;
decompress on first use, keep the `.raw` cached for subsequent starts.
2. QMP: same `mapped-ram` + `multifd` caps → `migrate-incoming
file:<.raw>` → poll for `paused` → `cont`.
3. Generate fresh per-install secrets on the host; pipe them
base64-encoded through QGA `guest-exec input-data` →
`trigger-fast-rotate` in the guest → `docker exec -e … rotate-secrets`.
4. `rotate-secrets` in the container: validate keys (hex-only), targeted
`sed` on the placeholder PCK across built JS, `UPDATE ApiKeySet`,
`supervisorctl restart stack-app cron-jobs` (with
`stopasgroup`/`killasgroup` so the Node children actually die and
release their ports).
5. Poll backend+dashboard health; if anything fails, clean up and fall
back to cold boot transparently.
**Security model**: placeholder hex values are baked into the snapshot
(`00…ff` PCK, `00…ee` SSK, `00…dd` SAK, `00…cc` CRON_SECRET). They are
non-secret by construction. Real per-install secrets are generated at
each `emulator start` and never leave the host.
## CLI changes (`packages/stack-cli`)
- **`src/lib/iso.ts`** (new): native TypeScript ISO 9660 + Joliet
writer, replacing the host-side `hdiutil`/`mkisofs`/`genisoimage`
dependency for generating the STACKCFG runtime config disk. Unit tests
in `src/lib/iso.test.ts`.
- **`src/commands/emulator.ts`**:
- `pull`: streamed downloads with progress bar + ETA; `--pr <number>`
and `--run <id>` to pull from a PR build's CI artifacts (uses
`extract-zip` for the nested zip); `--skip-snapshot` to opt out of the
one-time local capture.
- `start` (existing, extended): auto-pulls AND auto-captures when no
image exists, so first-ever `start` is self-bootstrapping; emits
`STACK_EMULATOR_CLI_WROTE_ISO=1` so the shell helper skips its own ISO
regen (avoids the genisoimage host dep).
- `capture` (new, invoked by `pull` and the auto-pull path of `start`):
drives the local snapshot capture via `run-emulator.sh`.
- `status`, `stop`, `reset`, `list-releases`: preflight +
path-resolution tightening (`STACK_EMULATOR_HOME` → images/run dirs).
- Unit tests in `src/commands/emulator.test.ts`.
- **`EMULATOR_NO_ROTATION=1`** env var skips the post-resume rotation
(intended for tests/CI where the placeholder secrets are fine — comes
with a loud warning).
## CI (`.github/workflows/qemu-emulator-build.yaml`)
- Builds **QEMU 10.2.2 from source** (cached), because
`mapped-ram`/`multifd` migration capabilities aren't available in the
distro's QEMU. Enables KVM on ubicloud runners so amd64 boots at
hardware speed.
- amd64 + arm64 both build on the same amd64 matrix
(`ubicloud-standard-8`); arm64 runs under cross-arch TCG (provisioning
only — boot/verify smoke test is amd64-only).
- Verification now runs through the CLI: `emulator start` → `emulator
status` → `emulator stop` against the freshly-built qcow2 (via
`STACK_EMULATOR_HOME` pointing at the workspace, so the CLI doesn't
silently auto-pull a prior release).
- Packages **only** the qcow2. No `.savevm.zst` upload / publish.
- Release notes updated.
## Key files
**Shell / guest:**
- `docker/local-emulator/qemu/build-image.sh` — snapshot-compatible
device topology + STACKCFG runtime ISO at build time
- `docker/local-emulator/qemu/run-emulator.sh` — `start`, `capture`,
`stop`, `reset`, `status`; `-incoming defer`, `.raw` cache, QGA-driven
rotation, cold-boot fallback
- `docker/local-emulator/qemu/common.sh` (new) — shared `qmp_session` +
`capture_vm_state` (factored out so build-image.sh and run-emulator.sh
share the capture path)
- `docker/local-emulator/qemu/cloud-init/emulator/user-data` —
placeholder secrets in snapshot mode, `wait-for-stack-ready`,
`trigger-fast-rotate`, qemu-guest-agent enabled
- `docker/local-emulator/rotate-secrets.sh` (new) — in-container
rotation (sed + UPDATE + supervisorctl)
- `docker/local-emulator/supervisord.conf` — `stopasgroup`/`killasgroup`
on `stack-app` and `cron-jobs`
- `docker/local-emulator/entrypoint.sh` — only mint CRON_SECRET if unset
(placeholder supplied in snapshot mode via --env-file)
- `docker/local-emulator/Dockerfile` — ships `rotate-secrets` to
`/usr/local/bin`
- `docker/server/entrypoint.sh` — source
`/run/stack-auth/rotated-secrets.env`; skip full-tree sentinel scan on
warm restarts via marker
**CLI:**
- `packages/stack-cli/src/lib/iso.ts` (new) + `iso.test.ts` (new)
- `packages/stack-cli/src/commands/emulator.ts` + `emulator.test.ts`
(new)
- `packages/stack-cli/vitest.config.ts` (new)
**CI:**
- `.github/workflows/qemu-emulator-build.yaml`
## Test plan
- [x] `docker/local-emulator/qemu/build-image.sh {amd64,arm64}` produces
`stack-emulator-<arch>.qcow2` with snapshot-compatible topology
- [x] `stack emulator pull` downloads qcow2 with progress, then captures
locally (~1–3 min) and writes `stack-emulator-<arch>.savevm.zst` in the
images dir
- [x] `stack emulator pull --skip-snapshot` stops after download
- [x] `stack emulator pull --pr <n>` / `--run <id>` pull from PR /
workflow run artifacts
- [x] `stack emulator start` on a fresh dir auto-pulls **and**
auto-captures, then starts; subsequent starts fast-resume in ~5–8s;
backend + dashboard return 200
- [x] `EMULATOR_NO_ROTATION=1 stack emulator start` completes in ~2.5s;
backend + dashboard return 200 with warning printed
- [x] Two consecutive `emulator start` invocations produce different PCK
values in the internal `ApiKeySet` row
- [x] `stack emulator status` / `stop` / `reset` resolve paths from
`STACK_EMULATOR_HOME`
- [x] Verified end-to-end on arm64 macOS under HVF (capture ~50s,
fast-resume ~6.5s)
- [x] `pnpm lint` and `pnpm typecheck` pass; stack-cli unit tests (iso +
emulator) pass
- [ ] CI green on this PR (qemu-emulator-build matrix, smoke test)
- [ ] `gh release download emulator-<branch>-latest` contains only
`stack-emulator-<arch>.qcow2` once this PR merges and publish runs
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
* **New Features**
* Snapshot fast-start/resume with optional warm-snapshot assets, runtime
ISO generation, and a cached QEMU build to speed emulator setup.
* CLI: streamed artifact downloads with progress, improved release/asset
handling, stronger preflight checks, and start/status/stop emulator
commands.
* Automated secret rotation and ability to apply rotated secrets at
container startup; supervisor control socket enabled.
* **Bug Fixes**
* More robust start/stop/resume flows with automatic fallback to cold
boot and improved process-group shutdown behavior.
* **Tests**
* New tests for CLI utilities and ISO image generation.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
## Summary
Fixes the Sentry `StackAssertionError: Failed to load monthly active
users for internal metrics` crash (ClickHouse OOM at the 7.2 GiB
per-query cap) and applies two related optimizations to other queries in
the same route while here. Adds a local benchmark harness that validates
correctness and measures peak memory / duration before & after.
## Root cause (the original Sentry error)
`loadMonthlyActiveUsers` was written as `SELECT user_id … GROUP BY
user_id` and then counting in Node via a `Set`. On a large project that
ships back millions of user_ids. Two failure modes stacked:
1. **Result materialization** — every distinct user_id had to be
buffered in the server before streaming to Node (~20 MiB of result for
450k users; much more at real scale).
2. **`JSONExtract(toJSONString(data), 'is_anonymous', 'UInt8')`** — the
`toJSONString(data)` per-row re-serialization of the entire nested JSON
column, billions of times, just to pull one boolean. Dominates
bytes-read.
Combined, on a single partition read from S3-backed MergeTree, this can
exceed ClickHouse's 7.2 GiB per-query memory cap. That's exactly what
the Sentry trace showed.
## Changes
### 1. Fix MAU query (`loadMonthlyActiveUsers`)
Moved counting to the server with
`uniqExact(sipHash64(normalized_user_id))` and pulled the JS-side
normalization (`lower`, `trim`, `isUuid`) into SQL. Picked `sipHash64`
after benchmarking 7 variants — it's exact (at <<2³² users) and halves
the uniqExact hash-state vs. raw string keys.
### 2. Fix 1 — `JSONExtract(toJSONString(data), …)` → direct
`CAST(data.is_anonymous, …)`
Applied everywhere the pattern appeared in the metrics route:
- `loadDailyActiveUsers`
- the `analyticsUserJoin` subquery
- the `nonAnonymousAnalyticsUserFilter`
- `analyticsOverview:topRegion`
- `analyticsOverview:online`
Semantics preserved (`coalesce(CAST(data.is_anonymous,
'Nullable(UInt8)'), 0)` matches `JSONExtract(…, 'UInt8')` behavior when
the field is missing).
### 3. Fix 3 — server-aggregate the split queries
`loadDailyActiveUsersSplit` and `loadDailyActiveTeamsSplit` used to ship
1.2M+ `(day, user_id)` rows back to Node just so the JS could bucket
them into new / retained / reactivated. Rewrote both as one CTE-style
query that returns 31 rows (one per day in the 30-day window) with the
counts precomputed.
**Minor semantic shift** (documented inline in `route.tsx`): \"new\" is
now based on the user's first-ever `\$token-refresh` event rather than
their Postgres `signedUpAt`. Agrees for users who log in immediately
after sign-up (the common case). Disagrees for the rare edge case of an
account that existed pre-window but never generated a `\$token-refresh`
until now — old code classified as \"reactivated,\" new code classifies
as \"new.\" Judged acceptable; can be revisited.
Postgres round-trips for `ProjectUser.signedUpAt` / `Team.createdAt` are
no longer needed for the split, and the 76 MiB-ish wire ship is gone.
### 4. Benchmark harness
(`apps/backend/scripts/benchmark-internal-metrics.ts`)
Local-only tool. Three modes:
- **MAU equivalence matrix** — 13 edge cases (empty, dedup, anonymous
filter, window boundary, null user_id, non-UUID user_id, case variation,
project isolation, missing/null `is_anonymous`, wrong event_type).
Asserts OLD pipeline and NEW query return the **same set** of users, not
just the same count.
- **MAU perf** — OLD vs NEW plus 6 other candidate variants (inline
regex, UUID keys, sipHash64, HLL sketches), reads `memory_usage` /
`read_rows` / `result_bytes` from `system.query_log` for each, prints a
ranked table.
- **Full-route benchmark** (`BENCH_ROUTE_QUERIES=1`) — runs every
ClickHouse query in `/internal/metrics` in three stages (BEFORE, AFTER,
candidate OPTIMIZED) against the same seed and prints per-query deltas
plus endpoint-level totals.
Seeds under a synthetic `project_id` so real data is never touched;
cleans up on exit via `ALTER TABLE … DELETE`.
## Benchmark results
### MAU query alone
Ran at two scales; set-equality verified (new query identifies the same
individual users, not just the same count).
| seed | MAU | peak memory (old → new) | bytes read | duration |
|---|---|---|---|---|
| 500k events | 89,939 | 158.7 MiB → 46.7 MiB (**3.4×**, −70%) | 175.7
MiB → 63.0 MiB (2.8×) | 483 ms → 76 ms (**6.4×**) |
| 2.5M events | 449,990 | 439.2 MiB → 281.4 MiB (1.56×, −36%) | 865.0
MiB → 310.9 MiB (2.8×) | 783 ms → 126 ms (**6.2×**) |
MAU variant bake-off at 2.5M events (all exact, all set-equal to OLD):
| variant | memory | duration | notes |
|---|---|---|---|
| v0_old (baseline) | 440 MiB | 567 ms | — |
| v1_uniqExact_string | 284 MiB | 110 ms | naive fix |
| v3_uniqExact_toUUID | 244 MiB | 153 ms | UUID keys, slower per-row |
| **v4_uniqExact_sipHash64** | **125 MiB** | **95 ms** | **shipped** |
| v5_uniq (HLL) ~approx | 30 MiB | 86 ms | −0.25% error |
| v6_uniqCombined ~approx | 31 MiB | 67 ms | −0.15% error |
### Full `/internal/metrics` route (2.7M events, 300k users + page-views
+ clicks + teams)
Ranked by BEFORE peak memory:
| query | mem BEFORE | mem AFTER | Δ mem | dur BEFORE | dur AFTER | Δ
dur |
|---|---|---|---|---|---|---|
| analyticsOverview:topReferrers | 588.1 MiB | 411.1 MiB | 1.43× | 1833
ms | 110 ms | **16.66×** |
| analyticsOverview:totalVisitors | 584.3 MiB | 403.5 MiB | 1.45× | 1829
ms | 121 ms | 15.12× |
| analyticsOverview:dailyEvents | 584.1 MiB | 403.7 MiB | 1.45× | 1897
ms | 140 ms | 13.55× |
| loadUsersByCountry | 393.1 MiB | 385.4 MiB | ≈same | 74 ms | 80 ms |
≈same |
| loadDailyActiveUsersSplit | 363.4 MiB | 396.8 MiB | *+9%* | 1966 ms |
356 ms | 5.52× |
| analyticsOverview:topRegion | 269.9 MiB | 106.4 MiB | 2.54× | 1602 ms
| 65 ms | 24.65× |
| loadDailyActiveUsers | 268.3 MiB | 84.0 MiB | 3.19× | 1111 ms | 44 ms
| 25.25× |
| loadDailyActiveTeamsSplit | 59.6 MiB | 78.1 MiB | *+31%* | 70 ms | 123
ms | *+76%* |
| loadMonthlyActiveUsers | 54.9 MiB | 54.9 MiB | ≈same | 68 ms | 56 ms |
≈same |
| analyticsOverview:online | 18.4 MiB | 5.8 MiB | 3.17× | 58 ms | 4 ms |
14.50× |
**Endpoint-level totals**
| metric | BEFORE | AFTER | Δ |
|---|---|---|---|
| Sum peak ClickHouse memory | 3.11 GiB | 2.28 GiB | **−27%** |
| **Max query duration** (endpoint wall-clock floor) | **1966 ms** |
**356 ms** | **−82%** (5.5×) |
| Sum query duration (total CPU) | 10508 ms | 1099 ms | **−90%** (9.6×)
|
| Bytes read | 10.70 GiB | 4.55 GiB | −57% |
| Bytes shipped to Node | 94.8 MiB | 44.2 KiB | **−99.95%** |
Both split queries show a small memory *regression* at this seed size
(the new server-side window-function + self-join has its own state cost
that's near break-even with \"materialize + ship\" at 300k users); at
prod scale the 76 MiB-ship saving dominates. Duration is unambiguously
better.
## Why we don't need to drop the `analyticsUserJoin` in this PR
The benchmark includes an OPTIMIZED stage that drops the LEFT JOIN and
trusts `e.data.is_anonymous` directly, which would shave another **1.2
GiB / 1.9× duration** off the endpoint. **But we can't ship that here**
— an audit of the client tracker
(`packages/js/src/lib/stack-app/apps/implementations/event-tracker.ts`)
confirmed `is_anonymous` is never set on client-emitted `$page-view` /
`$click` events. The JOIN is currently load-bearing. A follow-up PR will
enrich `is_anonymous` at the batch ingest endpoint using
`auth.user.is_anonymous`; after one metrics-window cycle (~30 days) the
JOIN can be dropped.
## Follow-up work (out of scope for this PR)
- **Batch-endpoint enrichment** + drop the analytics-overview LEFT JOIN
(est. further −53% endpoint memory, −46% duration per the benchmark).
- **Teams-split hash-variant count mismatch** — `sipHash64(team_id)`
variant of the teams split shows a count discrepancy vs. the
string-keyed version in the benchmark. Not blocking since teams-split is
only #8 by memory; needs a root-cause pass before shipping that
particular optimization.
- **`loadUsersByCountry` window bound** — currently scans every
`$token-refresh` event ever for the tenancy (no time filter). Bounding
to 30 days would bound memory growth with project age, but changes
semantics (\"country of latest login ever\" → \"in last 30 days\").
Deferred because it's product-facing.
## Snapshot changes in `internal-metrics.test.ts.snap`
The `should return metrics data with users` test signs in 10 users
today, then deletes one of them mid-test. Two small snapshot values
change on today's date; both are just a reclassification of that single
deleted user — the total (10 active users) is unchanged.
- **`daily_active_users_split.new[today]`: 9 → 10**
All 10 users really did sign in for the first time today. The old code
only counted 9 because the deleted user's Postgres row was gone by the
time the metrics query ran, so the old classifier couldn't see they were
created today. The new query looks at ClickHouse events directly, sees
the deleted user's first event was today, and counts them as new like
everyone else.
- **`daily_active_users_split.reactivated[today]`: 1 → 0**
No user was "reactivated" today — nobody was active on an earlier day
and came back. The old "1" was the deleted user falling into this bucket
by default (the old classifier had no other rule that fit them). The new
code correctly reports zero.
Totals match either way (9 + 1 = 10 + 0). We're moving one deleted user
out of the "returning visitor" bucket and into the "brand-new user"
bucket, which is what they actually were.
## Test plan
- [x] `pnpm typecheck` and `pnpm lint` pass on the backend package
- [x] MAU equivalence matrix: 13/13 cases return the same set of users
(not just the same count) between OLD and NEW pipelines
- [x] Set-equality verified at 500k-MAU perf scale
- [x] Full-route benchmark confirms the expected memory / duration
improvements
- [ ] Sanity-check the dashboard rendering after deploy (split charts,
MAU counter, analytics overview)
- [ ] Monitor Sentry for the assertion error — should drop to zero
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
* **Performance Improvements**
* Monthly and daily active metrics are now computed entirely server-side
for faster queries and reduced client-side processing.
* **Bug Fixes**
* More consistent handling of anonymous/missing IDs and stricter ID
filtering to improve accuracy across edge cases.
* **Tests**
* Added a comprehensive benchmark and validation harness to measure
query performance and verify result equivalence across variants.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
<!--
Make sure you've read the CONTRIBUTING.md guidelines:
https://github.com/stack-auth/stack-auth/blob/dev/CONTRIBUTING.md
-->
<!-- This is an auto-generated comment: release notes by coderabbit.ai
-->
## Summary by CodeRabbit
* **Refactor**
* Request sanitization now includes an extra proxy-specific
preprocessing step for safer AI proxying.
* **New Features**
* Initialization prompts centralized into a shared helper, with a
web-specific prompt variant.
* Authenticated requests can optionally route via a provided external
API key to access alternate models.
* **Chores**
* Added and exposed a preprocessing hook with a default no-op
implementation.
<!-- end of auto-generated comment: release notes by coderabbit.ai -->
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}