From ec815cdd35f6725e3187702f1802b60c2beabad3 Mon Sep 17 00:00:00 2001
From: Ilenia <26656284+ilenia-magoni@users.noreply.github.com>
Date: Mon, 11 Aug 2025 14:30:36 +0200
Subject: [PATCH] feat(curriculum): add working with common data structures
lectures (#61747)
Co-authored-by: Kolade Chris <65571316+Ksound22@users.noreply.github.com>
Co-authored-by: Jessica Wilkins <67210629+jdwilkin4@users.noreply.github.com>
---
.../meta.json | 29 +-
.../68420c314cdf5c6863ca8330.md | 202 ++++++++---
.../6895d06b5968736797c408e3.md | 237 +++++++++++++
.../6895d06b5968736797c408e4.md | 212 ++++++++++++
.../6895d06b5968736797c408e5.md | 195 +++++++++++
.../6895d06b5968736797c408e6.md | 231 +++++++++++++
.../6895d06b5968736797c408e7.md | 317 ++++++++++++++++++
7 files changed, 1377 insertions(+), 46 deletions(-)
create mode 100644 curriculum/challenges/english/25-front-end-development/lecture-working-with-common-data-structures/6895d06b5968736797c408e3.md
create mode 100644 curriculum/challenges/english/25-front-end-development/lecture-working-with-common-data-structures/6895d06b5968736797c408e4.md
create mode 100644 curriculum/challenges/english/25-front-end-development/lecture-working-with-common-data-structures/6895d06b5968736797c408e5.md
create mode 100644 curriculum/challenges/english/25-front-end-development/lecture-working-with-common-data-structures/6895d06b5968736797c408e6.md
create mode 100644 curriculum/challenges/english/25-front-end-development/lecture-working-with-common-data-structures/6895d06b5968736797c408e7.md
diff --git a/curriculum/challenges/_meta/lecture-working-with-common-data-structures/meta.json b/curriculum/challenges/_meta/lecture-working-with-common-data-structures/meta.json
index e09a0432b95..7e7e0f562cb 100644
--- a/curriculum/challenges/_meta/lecture-working-with-common-data-structures/meta.json
+++ b/curriculum/challenges/_meta/lecture-working-with-common-data-structures/meta.json
@@ -5,6 +5,31 @@
"blockType": "lecture",
"blockLayout": "challenge-list",
"superBlock": "full-stack-developer",
- "challengeOrder": [{ "id": "68420c314cdf5c6863ca8330", "title": "Step 1" }],
+ "challengeOrder": [
+ {
+ "id": "68420c314cdf5c6863ca8330",
+ "title": "What Is an Algorithm and How Does Big O Notation Work?"
+ },
+ {
+ "id": "6895d06b5968736797c408e3",
+ "title": "What Are Good Problem-Solving Techniques and Ways to Approach Algorithmic Challenges?"
+ },
+ {
+ "id": "6895d06b5968736797c408e4",
+ "title": "How Do Dynamic Arrays Differ From Static Arrays?"
+ },
+ {
+ "id": "6895d06b5968736797c408e5",
+ "title": "How Do Stacks and Queues Work?"
+ },
+ {
+ "id": "6895d06b5968736797c408e6",
+ "title": "How Do Singly Linked Lists Work and How Do They Differ From Doubly Linked List?"
+ },
+ {
+ "id": "6895d06b5968736797c408e7",
+ "title": "How Do Maps, Hash Maps and Sets Work?"
+ }
+ ],
"helpCategory": "Python"
-}
+}
\ No newline at end of file
diff --git a/curriculum/challenges/english/25-front-end-development/lecture-working-with-common-data-structures/68420c314cdf5c6863ca8330.md b/curriculum/challenges/english/25-front-end-development/lecture-working-with-common-data-structures/68420c314cdf5c6863ca8330.md
index 6313662e84b..09c30d748fe 100644
--- a/curriculum/challenges/english/25-front-end-development/lecture-working-with-common-data-structures/68420c314cdf5c6863ca8330.md
+++ b/curriculum/challenges/english/25-front-end-development/lecture-working-with-common-data-structures/68420c314cdf5c6863ca8330.md
@@ -1,135 +1,249 @@
---
id: 68420c314cdf5c6863ca8330
-# title needs to be updated to correct title when lectures are finalized
-title: Working with Common Data Structures
+title: What Is an Algorithm and How Does Big O Notation Work?
challengeType: 19
-# dashedName needs to be updated to correct title when lectures are finalized
-dashedName: lecture-working-with-common-data-structures
+dashedName: what-is-an-algorithm-and-how-does-big-o-notation-work
---
# --description--
-Watch the video or read the transcript and answer the questions below.
+Every computer program that runs on your device has a specific set of instructions, which are executed in a specific order to complete a task.
+
+The task could be sorting a set of numbers, modifying an image, tracking inventory, or even running your favorite video game.
+
+This is where algorithms come into play. An **algorithm** is a set of unambiguous instructions for solving a problem or carrying out a task.
+
+You can think of algorithms as "recipes". When you cook, recipes list all the ingredients that you'll need, and provide step by step instructions on how to prepare a dish.
+
+Equivalently, you can think of algorithms as "recipes" that tell computers exactly what should be done and how to do it.
+
+Algorithms have two key characteristics:
+
+* They cannot continue indefinitely. They must finish in a finite number of steps.
+
+* Each step must be precise and unambiguous.
+
+
+They may have zero, one, or more inputs, and generate one or more outputs.
+
+The steps of an algorithm are independent from any programming language.
+
+But to actually make them run on a computer, you need to implement them in a programming language, like Python or JavaScript.
+
+If an algorithm is correct, the output for any valid input should match the expected output.
+
+In addition to being correct, algorithms should also be efficient.
+
+Algorithm efficiency can be measured in terms of how long they take to run and how much space they require in memory to complete the task.
+
+Knowing an algorithm's efficiency is very important because it gives you an idea of how well it will perform as the input size grows.
+
+For example, sorting 15 integers is not the same as sorting 1 million integers.
+
+As the process grows in size and complexity, if the algorithm is not efficient enough to handle it, you might end up with a very slow computer program that may even crash the entire system.
+
+That's why it's very important to develop and choose the most efficient algorithms possible.
+
+This is where Big O notation becomes very important.
+
+Big O notation describes the worst-case performance, or growth rate, of an algorithm as the input size increases.
+
+The growth rate of an algorithm refers to how the resources it requires increase as the input size grows.
+
+Big O notation focuses on the worst-case performance because this case is very important to understand how efficient the algorithm can be, even in the worst case scenario, regardless of the input.
+
+Going back to our sorting example, sorting 1 million integers should intuitively take more time and resources than sorting 15 integers.
+
+But how much more?
+
+This really depends on the algorithm that you choose to sort them.
+
+Big O notation will not give you an exact number to describe the algorithm's efficiency, but it will give you an idea of how it scales as the input size grows, based on the number of operations performed by the algorithm.
+
+In Big O notation, we usually denote input size with the letter `n`. For example, if the input is a list, `n` would denote the number of elements in that list.
+
+Constant factors and lower-order terms are not taken into account to find the time complexity of an algorithm based on the number of operations. That's because as the size of `n` grows, the impact of these smaller terms in the total number of operations performed will become smaller and smaller.
+
+The term that will dominate the overall behavior of the algorithm will the term with `n`, the input size.
+
+For example, if an algorithm performs `7n + 20` operations to be completed, the impact of the constant `20` on the final result will be smaller and smaller as `n` grows. The term `7n` will tend to dominate and this will define the overall behavior and efficiency of the algorithm.
+
+Another example would be an algorithm that takes `20n² + 15n + 7` operations to be completed. The term `20n²` will tend to dominate as `n` grows, so this algorithm would have a quadratic time complexity because the dominant term has `n²`.
+
+Quadratic time complexity is one of many different types of time complexities that you can find in the world of algorithms.
+
+Let's learn about some of the most common ones.
+
+**`O(1)`** is known as "Constant Time Complexity". When an algorithm has constant time complexity, it takes the same amount of time to run, regardless of input size.
+
+For example, checking if a number is even or odd will always take the same amount of time, regardless of the number itself.
+
+```python
+def check_even_or_odd(number):
+ if number % 2 == 0:
+ return 'Even'
+ else:
+ return 'Odd'
+```
+
+**`O(log n)`** is known as "Logarithmic Time Complexity". This means that the time required by the algorithm increases slowly as the input size grows. This is common in problems in which the size of the problem is repeatedly reduced by a constant fraction.
+
+For example, a popular search algorithm called Binary Search has `O(log n)` worst-case time complexity. This is because it eliminates half of the remaining elements in each comparison, which makes it more efficient overall.
+
+**`O(n)`** is known as "Linear Time Complexity". The running time of algorithms with this time complexity increases proportionally to the input size.
+
+For example, a `for` loop that iterates over all the elements of a list will perform more iterations as the number of list elements increases. If the list is doubled in size, the number of operations will approximately double as well.
+
+```python
+for grade in grades: # grades is a list.
+ print(grade)
+```
+
+**`O(n log n)`** is known as "Log-Linear Time Complexity". This is a common time complexity of efficient sorting algorithms, like Merge Sort and Quick Sort.
+
+**`O(n²)`** is known as "Quadratic Time Complexity". The running time of these algorithms increases quadratically relative to the input size, which is generally not efficient for real-world problems.
+
+Nested loops are a common example of quadratic time complexity. The inner loop will perform `n` iterations for each one of the `n` iterations of the outer loop, resulting in `n` squared iterations.
+
+```python
+for i in range(n):
+ for j in range(n):
+ print("Hello, World!")
+```
+
+Other time complexities include "Exponential Time Complexity", denoted as `O(2^n)`, and "Factorial Time Complexity", denoted as `O(n!)`. Both are inefficient for real-world scenarios.
+
+In this graph, you can compare the growth of the mathematical functions that represent the most common time complexities. Think of the x-axis (horizontal) as the input size and the y-axis (vertical) as the running time of the algorithm.
+
+You can see that the Quadratic Time Complexity (`O(n²)`) (yellow) grows much faster than the other ones, while the Constant Time Complexity (`O(1)`) (red) stays constant, even if the input gets larger.
+
+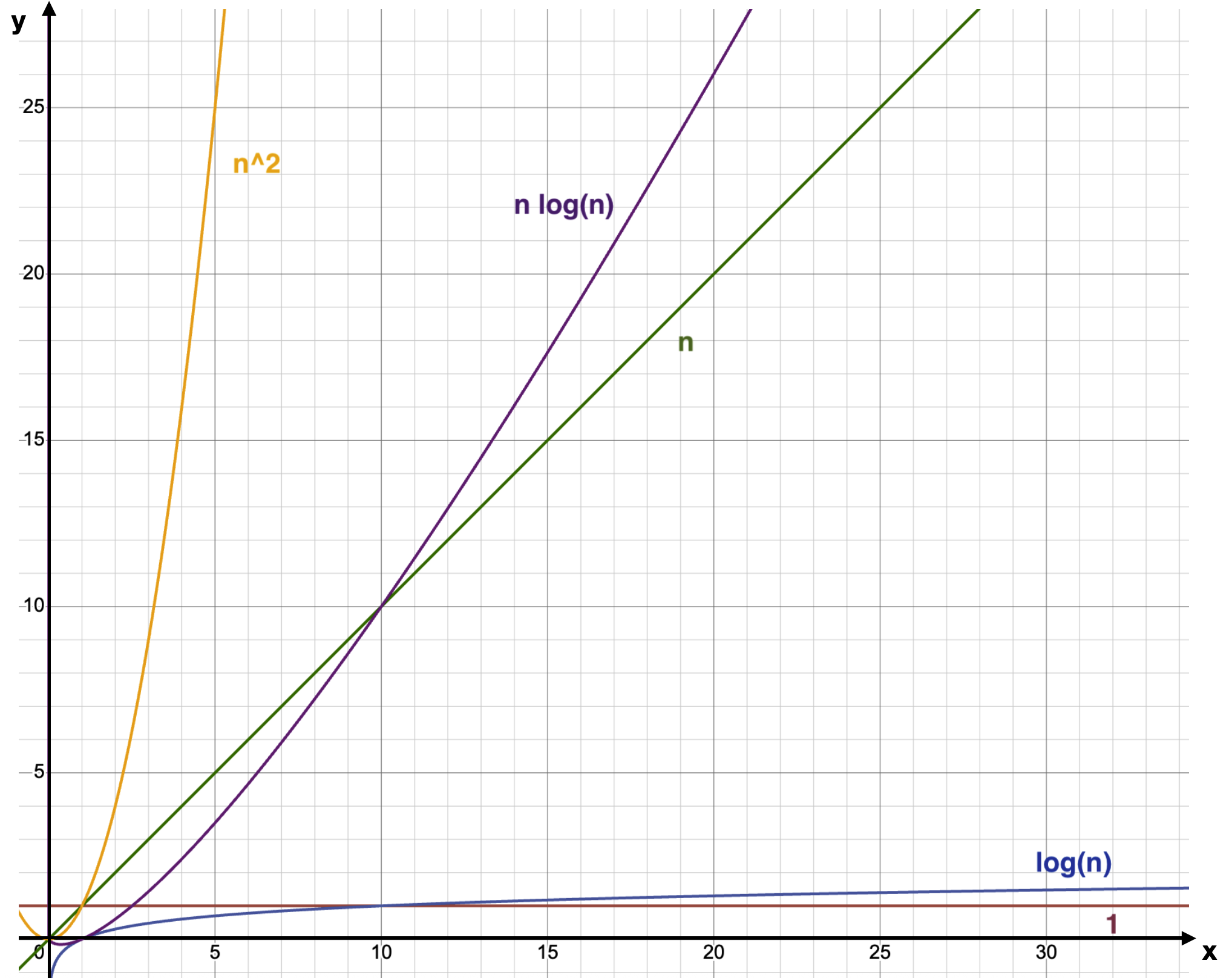 +
+Great. So far, you've learned about Big O notation in terms of time requirements, but this notation can also be applied to the context of space requirements.
+
+In this context, it describes how the memory space required by the algorithm grows as the input size grows.
+
+Algorithms with "Constant Space Complexity" `O(1)` always require a constant amount of memory space, even as the input gets larger.
+
+An example would be an algorithm that only creates and stores a few variables in memory.
+
+In contrast, the space required by algorithms with "Linear Space Complexity" `O(n)` increases proportionally as the input size grows.
+
+An example of this would be an algorithm that creates and stores a copy of a list of length `n`.
+
+And finally, the space requirements of an algorithm with "Quadratic Space Complexity" `O(n²)` increase quadratically as the input size grows.
+
+An example of this would be creating a 2D matrix, where the dimensions are determined by the input size, storing all possible pairs.
+
+Algorithms are the building-blocks of computer programs, while Big O notation is a powerful framework for analyzing how efficient they are, based on how their time and space requirements in the worst-case scenario scale as the input size grows. Understanding their efficiency is very important for developing software that works efficiently in real-world scenarios.
# --questions--
## --text--
-Question 1
+Which of the following best describes an algorithm?
## --answers--
-Answer 1.1
+A specific programming language used to write code.
### --feedback--
-Feedback 1
+Think about what you follow when you're trying to achieve a specific task.
---
-Answer 1.2
-
-### --feedback--
-
-Feedback 1
+A set of step-by-step instructions designed to solve a problem or perform a task.
---
-Answer 1.3
+A type of computer hardware component.
### --feedback--
-Feedback 1
+Think about what you follow when you're trying to achieve a specific task.
---
-Answer 1.4
+A software application used for developing and playing games.
### --feedback--
-Feedback 1
+Think about what you follow when you're trying to achieve a specific task.
## --video-solution--
-5
+2
## --text--
-Question 2
+What is the primary purpose of Big O notation in the context of algorithms?
## --answers--
-Answer 2.1
+To measure the exact time an algorithm takes to run on a specific computer in seconds.
### --feedback--
-Feedback 2
+Think about what Big O notation helps you understand an algorithm's performance when the amount of data it processes gets very large.
---
-Answer 2.2
+To count the total number of lines of code in an algorithm.
### --feedback--
-Feedback 2
+Think about what Big O notation helps you understand an algorithm's performance when the amount of data it processes gets very large.
---
-Answer 2.3
-
-### --feedback--
-
-Feedback 2
+To describe how the resource usage of an algorithm grows as the input size increases.
---
-Answer 2.4
+To determine the best-case performance of an algorithm.
### --feedback--
-Feedback 2
+Think about what Big O notation helps you understand an algorithm's performance when the amount of data it processes gets very large.
## --video-solution--
-5
+3
## --text--
-Question 3
+If an algorithm has a time complexity of `O(n)`, what does this mean about its performance?
## --answers--
-Answer 3.1
-
-### --feedback--
-
-Feedback 3
+The algorithm's running time increases proportionally with the input size.
---
-Answer 3.2
+The algorithm's running time remains constant regardless of the input size.
### --feedback--
-Feedback 3
+Think about what "linear" means in terms of a direct relationship or a straight line on a graph.
---
-Answer 3.3
+The algorithm's running time grows exponentially with the input size.
### --feedback--
-Feedback 3
+Think about what "linear" means in terms of a direct relationship or a straight line on a graph.
---
-Answer 3.4
+The algorithm's running time decreases as the input size gets larger.
### --feedback--
-Feedback 3
+Think about what "linear" means in terms of a direct relationship or a straight line on a graph.
## --video-solution--
-5
+1
diff --git a/curriculum/challenges/english/25-front-end-development/lecture-working-with-common-data-structures/6895d06b5968736797c408e3.md b/curriculum/challenges/english/25-front-end-development/lecture-working-with-common-data-structures/6895d06b5968736797c408e3.md
new file mode 100644
index 00000000000..2464157aa78
--- /dev/null
+++ b/curriculum/challenges/english/25-front-end-development/lecture-working-with-common-data-structures/6895d06b5968736797c408e3.md
@@ -0,0 +1,237 @@
+---
+id: 6895d06b5968736797c408e3
+title: What Are Good Problem-Solving Techniques and Ways to Approach Algorithmic Challenges?
+challengeType: 19
+dashedName: what-are-good-problem-solving-techniques-and-ways-to-approach-algorithmic-challenges
+---
+
+# --description--
+
+During your learning journey, you should work on developing strong problem-solving skills. These core skills will be essential for tackling real-world problems in your daily work.
+
+Solving algorithmic challenges is a great way to practice. It requires an analytical way of thinking, being able to break the problem down into its core components, and finding a solution that generates the right output efficiently.
+
+But where do you start?
+
+There are several problem-solving techniques that you can use to start approaching these challenges.
+
+As an example, we'll reverse a string in Python.
+
+This is the challenge:
+
+"Given a string, write an algorithm that returns a new string with the characters in reverse order."
+
+The first thing that you should do when you come across this type of problem is to read the description multiple times to make sure that you understand what it says. You may miss critical information if you skip this step or read it too fast.
+
+Then, once you are familiar with the problem, start breaking it down into its core components.
+
+Ask yourself:
+
+* "What is the input?"
+
+* "What is the expected output?"
+
+* "How can I transform the input into the expected output?"
+
+
+In this problem, you can determine that the input is a string because the challenge starts with "Given a string…"
+
+The output is "a new string with the characters in reverse order."
+
+So you need to take the original string and reverse it.
+
+This initial analysis might seem a bit repetitive at first, but it's very helpful to make sure that you fully understand the requirements.
+
+Then, you should start thinking about how the algorithm that you will develop will transform the input into the output.
+
+During this planning and analysis phase, it's common to use pseudocode to map out the necessary steps.
+
+**Pseudocode** is a high-level description of the algorithm's logic that is general in nature, and is not based on any specific programming language.
+
+Pseudocode is not as formal as actual code, since it's only intended for humans to read. It should be easy to understand at a glance. Its main purpose is to give a clear idea of the sequence of steps that will be performed.
+
+Pseudocode is usually a mixture of a common written language, like English, with programming constructs, like `IF`, `ELSE`, `FOR`, and `WHILE`.
+
+This is an example of pseudocode that you may write to solve the "Reverse a String" challenge.
+
+```md
+GET original_string
+
+SET reversed_string = ""
+
+FOR EACH character IN original_string:
+ ADD character TO THE BEGINNING OF reversed_string
+
+DISPLAY reversed_string
+```
+
+Note how the steps are outlined in a way that is easy to understand. The words and constructs themselves might vary depending on the standards that you are following.
+
+If you wanted to, you could implement these steps in multiple programming languages following the same logic, since the pseudocode is independent of the programming language.
+
+By this point, you may have already realized that this problem can be solved in many different ways. This isn't the only way to reverse a string.
+
+But remember that choosing the right algorithm is important.
+
+In a previous lecture, you learned about algorithmic complexity and why it is important to choose algorithms that are efficient in terms of time and space.
+
+That's where you will play a vital role as a developer. You will need to choose the most efficient algorithm to solve the challenge.
+
+Thinking through different available algorithms is an important problem-solving skill that you should practice. Take a moment to ask yourself if the solution that you are proposing in your pseudocode is the best one or not.
+
+For example, there are many different algorithms for sorting elements, but some of them are more efficient than others. Bubble sort, for example, is very inefficient for sorting large lists, while Quick Sort is usually more efficient.
+
+For our "Reverse a String" challenge, we could use either one of these approaches, assuming that we are planning to implement our algorithm in Python:
+
+* Using the extended slice syntax `[::-1]` to get a new reversed string.
+
+* Looping over the characters from left to right and adding the new character to the beginning of the new string.
+
+* Calling the `reversed()` function to get an iterator with all the characters in reverse order, and then the `““.join()` method to concatenate them back into a string.
+
+
+Which one should you use? That's your choice.
+
+Making these decisions based on your knowledge and experience can make a huge difference in the final performance of your application. Consider different approaches, their efficiency, implications, and implementation.
+
+Ask yourself:
+
+* "How will I approach this problem?"
+
+* "What data structures will I use?"
+
+* "Are the data structures that I chose the most efficient ones for the problem at hand?"
+
+* "Am I covering all possible edge cases?"
+
+
+Edge cases are specific, valid inputs or conditions that occur at the boundaries of what an algorithm should handle.
+
+For example, in the "Reverse a String" challenge, an edge case would be taking an empty string as input. Are you handling this correctly? If not, consider the best way to handle this edge case and add it to your pseudocode.
+
+Then, once you are happy with your plan, you can move on to the implementation phase. At this phase, you will implement your algorithm in a programming language.
+
+When structuring your program, you should write modular code that is easy to read and understand.
+
+Use the tools of the programming language based on your current knowledge. Some programming languages include built-in solutions for common problems and tasks. Use them if possible.
+
+To be consistent, follow the best practices of the programming language of your choice.
+
+Test your code as you write it and make sure that you are handling edge cases appropriately.
+
+Once your solution is implemented, check if it works correctly for all the examples and potentially refactor your code to make it clearer or simpler.
+
+Going back to your solution is very important. Development is not necessarily a linear, step-by-step process. You can always go back to your code and use your critical thinking skills to improve it.
+
+These are some common problem-solving techniques that you can follow to approach algorithmic challenges. If you practice consistently, you will gradually develop your problem-solving skills.
+
+# --questions--
+
+## --text--
+
+Which of the following is the most important first step when approaching any problem-solving challenge?
+
+## --answers--
+
+Understand the problem statement, inputs, and constraints.
+
+---
+
+Search for existing solutions online.
+
+### --feedback--
+
+What should you do before you even think about solutions?
+
+---
+
+Immediately start writing code.
+
+### --feedback--
+
+What should you do before you even think about solutions?
+
+---
+
+Guess a solution and then try to make it work.
+
+### --feedback--
+
+What should you do before you even think about solutions?
+
+## --video-solution--
+
+1
+
+## --text--
+
+What is the main purpose of writing pseudocode when solving an algorithmic challenge?
+
+## --answers--
+
+To write the final, executable version of the code.
+
+### --feedback--
+
+Think about what pseudocode helps you do before you start writing code.
+
+---
+
+To test the algorithm's performance and find bugs.
+
+### --feedback--
+
+Think about what pseudocode helps you do before you start writing code.
+
+---
+
+To outline the algorithm's logic in a human-readable, language-agnostic way.
+
+---
+
+To automatically generate the actual code for the solution.
+
+### --feedback--
+
+Think about what pseudocode helps you do before you start writing code.
+
+## --video-solution--
+
+3
+
+## --text--
+
+Before writing the final code for an algorithmic challenge, why is it important to consider edge cases?
+
+## --answers--
+
+Edge cases are always the easiest parts of the problem to solve.
+
+### --feedback--
+
+Think about what kind of inputs might cause unexpected behavior if they are not specifically considered, even if they are valid.
+
+---
+
+They help ensure the algorithm works correctly for all valid inputs.
+
+---
+
+They are only relevant for very simple problems.
+
+### --feedback--
+
+Think about what kind of inputs might cause unexpected behavior if they are not specifically considered, even if they are valid.
+
+---
+
+They make the code shorter.
+
+### --feedback--
+
+Think about what kind of inputs might cause unexpected behavior if they are not specifically considered, even if they are valid.
+
+## --video-solution--
+
+2
+
diff --git a/curriculum/challenges/english/25-front-end-development/lecture-working-with-common-data-structures/6895d06b5968736797c408e4.md b/curriculum/challenges/english/25-front-end-development/lecture-working-with-common-data-structures/6895d06b5968736797c408e4.md
new file mode 100644
index 00000000000..258d23311a3
--- /dev/null
+++ b/curriculum/challenges/english/25-front-end-development/lecture-working-with-common-data-structures/6895d06b5968736797c408e4.md
@@ -0,0 +1,212 @@
+---
+id: 6895d06b5968736797c408e4
+title: How Do Dynamic Arrays Differ From Static Arrays?
+challengeType: 19
+dashedName: how-do-dynamic-arrays-differ-from-static-arrays
+---
+
+# --description--
+
+Arrays are a fundamental data structure in computer science. All arrays store ordered collections of data, but depending on their type, they may work differently behind the scenes.
+
+Their underlying behavior can have an important effect in the program's efficiency, so let's learn about dynamic and static arrays and their differences, so you can choose the most efficient one for your program.
+
+We'll start with static arrays.
+
+**Static arrays** have a fixed size. They store elements in adjacent memory locations.
+
+The size of a static array is determined when the array is initialized. Once that specific block of memory is allocated, it's fixed, and cannot be changed while the program is running. This is a key characteristic of static arrays.
+
+Storing elements in adjacent memory locations makes the data retrieval process more efficient because the program can store the location of the first element and then use indices to make simple calculations and find the other elements in memory.
+
+Thanks to this, accessing the values of a static array takes constant time `O(1)`, which is very efficient.
+
+You can use a static array when you know the number of elements that will be stored in advance. It's also helpful when the values will be accessed very frequently, since the access operation is very efficient.
+
+However, this data structure cannot grow or shrink, so if the number of elements that will be stored can vary, you should use a dynamic array instead.
+
+Trying to increase the size of a static array would involve creating a new array and copying all the elements from the old array to a new one, which is inefficient. In that case, a dynamic array would be much better because it handles this process automatically.
+
+Python does not include traditional static arrays as built-in data structures.
+
+But other programming languages, like Java, do support them. This is an example of a static array in Java that can store three integers:
+
+```java
+int[] numbers = new int[3];
+```
+
+Arrays in Python are dynamic, so let's take a look at those.
+
+**Dynamic arrays** are more flexible because they can grow or shrink automatically while the program is running.
+
+They work through an automatic resizing mechanism that copies the elements into a new array when the original array is full. The process is done efficiently because the size of the new array is chosen in an efficient way that makes these computationally expensive operations less frequent.
+
+Accessing the elements of a dynamic array takes constant time `O(1)`, so this operation is very efficient.
+
+Inserting an element in the middle of the array takes linear time `O(n)` because the elements after it need to be relocated.
+
+Inserting an element at the end of the array takes constant time `O(1)` if there is still space available in the dynamic array, but if the array is full and needs resizing, this operation has a `O(n)` complexity.
+
+You should use dynamic arrays when you don't know in advance the number of values that you will need to store in the array. They are also helpful when you will be frequently inserting and deleting elements.
+
+Python's built-in `list` data structure works as a dynamic array. You can create a list by writing the elements within square brackets, separated by commas.
+
+```python
+numbers = [3, 4, 5, 6]
+```
+
+You can access an element by writing the name of the variable that holds the list, followed by square brackets, and within the square brackets, the corresponding index.
+
+Indices start from 0 for the first element and are incremented by 1 for each subsequent element:
+
+```python
+numbers[0] # 3
+numbers[1] # 4
+numbers[2] # 5
+numbers[3] # 6
+```
+
+To update a value, you just need to reassign it:
+
+```python
+numbers[2] = 16
+```
+
+You can append elements to the list with the `.append()` method:
+
+```python
+numbers.append(7)
+```
+
+You can insert elements at a specific index with the `.insert()` method, passing the index as the first argument and the element itself as the second argument.
+
+```python
+numbers.insert(3, 15)
+```
+
+You can remove an element at a specific index with the `.pop()` method:
+
+```python
+numbers.pop(2)
+```
+
+If you don't specify the index, `.pop()` will remove the last element.
+
+There are other built-in list methods that you can check in the documentation for adding and removing elements quite easily.
+
+That's the power of dynamic arrays, or lists in this case.
+
+In general, you should use static arrays when you know the number of elements in advance and you need to access them frequently, and use dynamic arrays when the number of elements is unknown or variable over time.
+
+You should always consider the tradeoff between the simplicity of static arrays and the flexibility of dynamic arrays. They are both helpful for specific use cases and scenarios. Being able to choose the best one for a given problem is part of the problem-solving skills that you will gradually develop with practice.
+
+# --questions--
+
+## --text--
+
+What is the main difference in size between a static array and a dynamic array?
+
+## --answers--
+
+Static arrays can change their size after being created, while dynamic arrays cannot.
+
+### --feedback--
+
+Think about how much space each type of array will require.
+
+---
+
+Static arrays have a fixed size, while dynamic arrays can change size during runtime.
+
+---
+
+There is no practical difference in how their sizes are handled.
+
+### --feedback--
+
+Think about how much space each type of array will require.
+
+---
+
+Dynamic arrays are always larger than static arrays.
+
+### --feedback--
+
+Think about how much space each type of array will require.
+
+## --video-solution--
+
+2
+
+## --text--
+
+If you need to add more elements to a static array that is already full, what is the typical process involved?
+
+## --answers--
+
+The static array automatically expands its memory to fit the new elements.
+
+### --feedback--
+
+Think about what is necessary when a container with a fixed capacity runs out of space.
+
+---
+
+You must create a new, larger array and copy all existing elements to it.
+
+---
+
+The array automatically converts itself into a dynamic array.
+
+### --feedback--
+
+Think about what is necessary when a container with a fixed capacity runs out of space.
+
+---
+
+New elements are simply discarded if the array is full.
+
+### --feedback--
+
+Think about what is necessary when a container with a fixed capacity runs out of space.
+
+## --video-solution--
+
+2
+
+## --text--
+
+In which scenario would a static array typically be a more suitable choice than a dynamic array?
+
+## --answers--
+
+When the exact number of elements is unknown and changes frequently.
+
+### --feedback--
+
+Think about the main advantage of a static array related to its size and resource usage.
+
+---
+
+When you need to store a very large dataset that might grow indefinitely.
+
+### --feedback--
+
+Think about the main advantage of a static array related to its size and resource usage.
+
+---
+
+When you require frequent insertions and deletions at arbitrary positions within the collection.
+
+### --feedback--
+
+Think about the main advantage of a static array related to its size and resource usage.
+
+---
+
+When the data size is fixed and known at the time the program is written.
+
+## --video-solution--
+
+4
+
diff --git a/curriculum/challenges/english/25-front-end-development/lecture-working-with-common-data-structures/6895d06b5968736797c408e5.md b/curriculum/challenges/english/25-front-end-development/lecture-working-with-common-data-structures/6895d06b5968736797c408e5.md
new file mode 100644
index 00000000000..e6b3312b9ad
--- /dev/null
+++ b/curriculum/challenges/english/25-front-end-development/lecture-working-with-common-data-structures/6895d06b5968736797c408e5.md
@@ -0,0 +1,195 @@
+---
+id: 6895d06b5968736797c408e5
+title: How Do Stacks and Queues Work?
+challengeType: 19
+dashedName: how-do-stacks-and-queues-work
+---
+
+# --description--
+
+Stacks and queues are data structures commonly used in computer science.
+
+They're linear data structures that follow specific rules for adding and removing elements.
+
+## Stacks
+
+Let's start with **Stacks**.
+
+A **stack** is a Last-in, First-out (LIFO) data structure.
+
+This means that the last element that was added to the stack is the first one to be removed.
+
+Stacks have two ends, which we know as top and bottom.
+
+Elements are added and removed from the top of the stack.
+
+You can think of a stack as a pile of dishes, where you can only place dishes at the top of the pile and take dishes from the top of the pile.
+
+
+
+Great. So far, you've learned about Big O notation in terms of time requirements, but this notation can also be applied to the context of space requirements.
+
+In this context, it describes how the memory space required by the algorithm grows as the input size grows.
+
+Algorithms with "Constant Space Complexity" `O(1)` always require a constant amount of memory space, even as the input gets larger.
+
+An example would be an algorithm that only creates and stores a few variables in memory.
+
+In contrast, the space required by algorithms with "Linear Space Complexity" `O(n)` increases proportionally as the input size grows.
+
+An example of this would be an algorithm that creates and stores a copy of a list of length `n`.
+
+And finally, the space requirements of an algorithm with "Quadratic Space Complexity" `O(n²)` increase quadratically as the input size grows.
+
+An example of this would be creating a 2D matrix, where the dimensions are determined by the input size, storing all possible pairs.
+
+Algorithms are the building-blocks of computer programs, while Big O notation is a powerful framework for analyzing how efficient they are, based on how their time and space requirements in the worst-case scenario scale as the input size grows. Understanding their efficiency is very important for developing software that works efficiently in real-world scenarios.
# --questions--
## --text--
-Question 1
+Which of the following best describes an algorithm?
## --answers--
-Answer 1.1
+A specific programming language used to write code.
### --feedback--
-Feedback 1
+Think about what you follow when you're trying to achieve a specific task.
---
-Answer 1.2
-
-### --feedback--
-
-Feedback 1
+A set of step-by-step instructions designed to solve a problem or perform a task.
---
-Answer 1.3
+A type of computer hardware component.
### --feedback--
-Feedback 1
+Think about what you follow when you're trying to achieve a specific task.
---
-Answer 1.4
+A software application used for developing and playing games.
### --feedback--
-Feedback 1
+Think about what you follow when you're trying to achieve a specific task.
## --video-solution--
-5
+2
## --text--
-Question 2
+What is the primary purpose of Big O notation in the context of algorithms?
## --answers--
-Answer 2.1
+To measure the exact time an algorithm takes to run on a specific computer in seconds.
### --feedback--
-Feedback 2
+Think about what Big O notation helps you understand an algorithm's performance when the amount of data it processes gets very large.
---
-Answer 2.2
+To count the total number of lines of code in an algorithm.
### --feedback--
-Feedback 2
+Think about what Big O notation helps you understand an algorithm's performance when the amount of data it processes gets very large.
---
-Answer 2.3
-
-### --feedback--
-
-Feedback 2
+To describe how the resource usage of an algorithm grows as the input size increases.
---
-Answer 2.4
+To determine the best-case performance of an algorithm.
### --feedback--
-Feedback 2
+Think about what Big O notation helps you understand an algorithm's performance when the amount of data it processes gets very large.
## --video-solution--
-5
+3
## --text--
-Question 3
+If an algorithm has a time complexity of `O(n)`, what does this mean about its performance?
## --answers--
-Answer 3.1
-
-### --feedback--
-
-Feedback 3
+The algorithm's running time increases proportionally with the input size.
---
-Answer 3.2
+The algorithm's running time remains constant regardless of the input size.
### --feedback--
-Feedback 3
+Think about what "linear" means in terms of a direct relationship or a straight line on a graph.
---
-Answer 3.3
+The algorithm's running time grows exponentially with the input size.
### --feedback--
-Feedback 3
+Think about what "linear" means in terms of a direct relationship or a straight line on a graph.
---
-Answer 3.4
+The algorithm's running time decreases as the input size gets larger.
### --feedback--
-Feedback 3
+Think about what "linear" means in terms of a direct relationship or a straight line on a graph.
## --video-solution--
-5
+1
diff --git a/curriculum/challenges/english/25-front-end-development/lecture-working-with-common-data-structures/6895d06b5968736797c408e3.md b/curriculum/challenges/english/25-front-end-development/lecture-working-with-common-data-structures/6895d06b5968736797c408e3.md
new file mode 100644
index 00000000000..2464157aa78
--- /dev/null
+++ b/curriculum/challenges/english/25-front-end-development/lecture-working-with-common-data-structures/6895d06b5968736797c408e3.md
@@ -0,0 +1,237 @@
+---
+id: 6895d06b5968736797c408e3
+title: What Are Good Problem-Solving Techniques and Ways to Approach Algorithmic Challenges?
+challengeType: 19
+dashedName: what-are-good-problem-solving-techniques-and-ways-to-approach-algorithmic-challenges
+---
+
+# --description--
+
+During your learning journey, you should work on developing strong problem-solving skills. These core skills will be essential for tackling real-world problems in your daily work.
+
+Solving algorithmic challenges is a great way to practice. It requires an analytical way of thinking, being able to break the problem down into its core components, and finding a solution that generates the right output efficiently.
+
+But where do you start?
+
+There are several problem-solving techniques that you can use to start approaching these challenges.
+
+As an example, we'll reverse a string in Python.
+
+This is the challenge:
+
+"Given a string, write an algorithm that returns a new string with the characters in reverse order."
+
+The first thing that you should do when you come across this type of problem is to read the description multiple times to make sure that you understand what it says. You may miss critical information if you skip this step or read it too fast.
+
+Then, once you are familiar with the problem, start breaking it down into its core components.
+
+Ask yourself:
+
+* "What is the input?"
+
+* "What is the expected output?"
+
+* "How can I transform the input into the expected output?"
+
+
+In this problem, you can determine that the input is a string because the challenge starts with "Given a string…"
+
+The output is "a new string with the characters in reverse order."
+
+So you need to take the original string and reverse it.
+
+This initial analysis might seem a bit repetitive at first, but it's very helpful to make sure that you fully understand the requirements.
+
+Then, you should start thinking about how the algorithm that you will develop will transform the input into the output.
+
+During this planning and analysis phase, it's common to use pseudocode to map out the necessary steps.
+
+**Pseudocode** is a high-level description of the algorithm's logic that is general in nature, and is not based on any specific programming language.
+
+Pseudocode is not as formal as actual code, since it's only intended for humans to read. It should be easy to understand at a glance. Its main purpose is to give a clear idea of the sequence of steps that will be performed.
+
+Pseudocode is usually a mixture of a common written language, like English, with programming constructs, like `IF`, `ELSE`, `FOR`, and `WHILE`.
+
+This is an example of pseudocode that you may write to solve the "Reverse a String" challenge.
+
+```md
+GET original_string
+
+SET reversed_string = ""
+
+FOR EACH character IN original_string:
+ ADD character TO THE BEGINNING OF reversed_string
+
+DISPLAY reversed_string
+```
+
+Note how the steps are outlined in a way that is easy to understand. The words and constructs themselves might vary depending on the standards that you are following.
+
+If you wanted to, you could implement these steps in multiple programming languages following the same logic, since the pseudocode is independent of the programming language.
+
+By this point, you may have already realized that this problem can be solved in many different ways. This isn't the only way to reverse a string.
+
+But remember that choosing the right algorithm is important.
+
+In a previous lecture, you learned about algorithmic complexity and why it is important to choose algorithms that are efficient in terms of time and space.
+
+That's where you will play a vital role as a developer. You will need to choose the most efficient algorithm to solve the challenge.
+
+Thinking through different available algorithms is an important problem-solving skill that you should practice. Take a moment to ask yourself if the solution that you are proposing in your pseudocode is the best one or not.
+
+For example, there are many different algorithms for sorting elements, but some of them are more efficient than others. Bubble sort, for example, is very inefficient for sorting large lists, while Quick Sort is usually more efficient.
+
+For our "Reverse a String" challenge, we could use either one of these approaches, assuming that we are planning to implement our algorithm in Python:
+
+* Using the extended slice syntax `[::-1]` to get a new reversed string.
+
+* Looping over the characters from left to right and adding the new character to the beginning of the new string.
+
+* Calling the `reversed()` function to get an iterator with all the characters in reverse order, and then the `““.join()` method to concatenate them back into a string.
+
+
+Which one should you use? That's your choice.
+
+Making these decisions based on your knowledge and experience can make a huge difference in the final performance of your application. Consider different approaches, their efficiency, implications, and implementation.
+
+Ask yourself:
+
+* "How will I approach this problem?"
+
+* "What data structures will I use?"
+
+* "Are the data structures that I chose the most efficient ones for the problem at hand?"
+
+* "Am I covering all possible edge cases?"
+
+
+Edge cases are specific, valid inputs or conditions that occur at the boundaries of what an algorithm should handle.
+
+For example, in the "Reverse a String" challenge, an edge case would be taking an empty string as input. Are you handling this correctly? If not, consider the best way to handle this edge case and add it to your pseudocode.
+
+Then, once you are happy with your plan, you can move on to the implementation phase. At this phase, you will implement your algorithm in a programming language.
+
+When structuring your program, you should write modular code that is easy to read and understand.
+
+Use the tools of the programming language based on your current knowledge. Some programming languages include built-in solutions for common problems and tasks. Use them if possible.
+
+To be consistent, follow the best practices of the programming language of your choice.
+
+Test your code as you write it and make sure that you are handling edge cases appropriately.
+
+Once your solution is implemented, check if it works correctly for all the examples and potentially refactor your code to make it clearer or simpler.
+
+Going back to your solution is very important. Development is not necessarily a linear, step-by-step process. You can always go back to your code and use your critical thinking skills to improve it.
+
+These are some common problem-solving techniques that you can follow to approach algorithmic challenges. If you practice consistently, you will gradually develop your problem-solving skills.
+
+# --questions--
+
+## --text--
+
+Which of the following is the most important first step when approaching any problem-solving challenge?
+
+## --answers--
+
+Understand the problem statement, inputs, and constraints.
+
+---
+
+Search for existing solutions online.
+
+### --feedback--
+
+What should you do before you even think about solutions?
+
+---
+
+Immediately start writing code.
+
+### --feedback--
+
+What should you do before you even think about solutions?
+
+---
+
+Guess a solution and then try to make it work.
+
+### --feedback--
+
+What should you do before you even think about solutions?
+
+## --video-solution--
+
+1
+
+## --text--
+
+What is the main purpose of writing pseudocode when solving an algorithmic challenge?
+
+## --answers--
+
+To write the final, executable version of the code.
+
+### --feedback--
+
+Think about what pseudocode helps you do before you start writing code.
+
+---
+
+To test the algorithm's performance and find bugs.
+
+### --feedback--
+
+Think about what pseudocode helps you do before you start writing code.
+
+---
+
+To outline the algorithm's logic in a human-readable, language-agnostic way.
+
+---
+
+To automatically generate the actual code for the solution.
+
+### --feedback--
+
+Think about what pseudocode helps you do before you start writing code.
+
+## --video-solution--
+
+3
+
+## --text--
+
+Before writing the final code for an algorithmic challenge, why is it important to consider edge cases?
+
+## --answers--
+
+Edge cases are always the easiest parts of the problem to solve.
+
+### --feedback--
+
+Think about what kind of inputs might cause unexpected behavior if they are not specifically considered, even if they are valid.
+
+---
+
+They help ensure the algorithm works correctly for all valid inputs.
+
+---
+
+They are only relevant for very simple problems.
+
+### --feedback--
+
+Think about what kind of inputs might cause unexpected behavior if they are not specifically considered, even if they are valid.
+
+---
+
+They make the code shorter.
+
+### --feedback--
+
+Think about what kind of inputs might cause unexpected behavior if they are not specifically considered, even if they are valid.
+
+## --video-solution--
+
+2
+
diff --git a/curriculum/challenges/english/25-front-end-development/lecture-working-with-common-data-structures/6895d06b5968736797c408e4.md b/curriculum/challenges/english/25-front-end-development/lecture-working-with-common-data-structures/6895d06b5968736797c408e4.md
new file mode 100644
index 00000000000..258d23311a3
--- /dev/null
+++ b/curriculum/challenges/english/25-front-end-development/lecture-working-with-common-data-structures/6895d06b5968736797c408e4.md
@@ -0,0 +1,212 @@
+---
+id: 6895d06b5968736797c408e4
+title: How Do Dynamic Arrays Differ From Static Arrays?
+challengeType: 19
+dashedName: how-do-dynamic-arrays-differ-from-static-arrays
+---
+
+# --description--
+
+Arrays are a fundamental data structure in computer science. All arrays store ordered collections of data, but depending on their type, they may work differently behind the scenes.
+
+Their underlying behavior can have an important effect in the program's efficiency, so let's learn about dynamic and static arrays and their differences, so you can choose the most efficient one for your program.
+
+We'll start with static arrays.
+
+**Static arrays** have a fixed size. They store elements in adjacent memory locations.
+
+The size of a static array is determined when the array is initialized. Once that specific block of memory is allocated, it's fixed, and cannot be changed while the program is running. This is a key characteristic of static arrays.
+
+Storing elements in adjacent memory locations makes the data retrieval process more efficient because the program can store the location of the first element and then use indices to make simple calculations and find the other elements in memory.
+
+Thanks to this, accessing the values of a static array takes constant time `O(1)`, which is very efficient.
+
+You can use a static array when you know the number of elements that will be stored in advance. It's also helpful when the values will be accessed very frequently, since the access operation is very efficient.
+
+However, this data structure cannot grow or shrink, so if the number of elements that will be stored can vary, you should use a dynamic array instead.
+
+Trying to increase the size of a static array would involve creating a new array and copying all the elements from the old array to a new one, which is inefficient. In that case, a dynamic array would be much better because it handles this process automatically.
+
+Python does not include traditional static arrays as built-in data structures.
+
+But other programming languages, like Java, do support them. This is an example of a static array in Java that can store three integers:
+
+```java
+int[] numbers = new int[3];
+```
+
+Arrays in Python are dynamic, so let's take a look at those.
+
+**Dynamic arrays** are more flexible because they can grow or shrink automatically while the program is running.
+
+They work through an automatic resizing mechanism that copies the elements into a new array when the original array is full. The process is done efficiently because the size of the new array is chosen in an efficient way that makes these computationally expensive operations less frequent.
+
+Accessing the elements of a dynamic array takes constant time `O(1)`, so this operation is very efficient.
+
+Inserting an element in the middle of the array takes linear time `O(n)` because the elements after it need to be relocated.
+
+Inserting an element at the end of the array takes constant time `O(1)` if there is still space available in the dynamic array, but if the array is full and needs resizing, this operation has a `O(n)` complexity.
+
+You should use dynamic arrays when you don't know in advance the number of values that you will need to store in the array. They are also helpful when you will be frequently inserting and deleting elements.
+
+Python's built-in `list` data structure works as a dynamic array. You can create a list by writing the elements within square brackets, separated by commas.
+
+```python
+numbers = [3, 4, 5, 6]
+```
+
+You can access an element by writing the name of the variable that holds the list, followed by square brackets, and within the square brackets, the corresponding index.
+
+Indices start from 0 for the first element and are incremented by 1 for each subsequent element:
+
+```python
+numbers[0] # 3
+numbers[1] # 4
+numbers[2] # 5
+numbers[3] # 6
+```
+
+To update a value, you just need to reassign it:
+
+```python
+numbers[2] = 16
+```
+
+You can append elements to the list with the `.append()` method:
+
+```python
+numbers.append(7)
+```
+
+You can insert elements at a specific index with the `.insert()` method, passing the index as the first argument and the element itself as the second argument.
+
+```python
+numbers.insert(3, 15)
+```
+
+You can remove an element at a specific index with the `.pop()` method:
+
+```python
+numbers.pop(2)
+```
+
+If you don't specify the index, `.pop()` will remove the last element.
+
+There are other built-in list methods that you can check in the documentation for adding and removing elements quite easily.
+
+That's the power of dynamic arrays, or lists in this case.
+
+In general, you should use static arrays when you know the number of elements in advance and you need to access them frequently, and use dynamic arrays when the number of elements is unknown or variable over time.
+
+You should always consider the tradeoff between the simplicity of static arrays and the flexibility of dynamic arrays. They are both helpful for specific use cases and scenarios. Being able to choose the best one for a given problem is part of the problem-solving skills that you will gradually develop with practice.
+
+# --questions--
+
+## --text--
+
+What is the main difference in size between a static array and a dynamic array?
+
+## --answers--
+
+Static arrays can change their size after being created, while dynamic arrays cannot.
+
+### --feedback--
+
+Think about how much space each type of array will require.
+
+---
+
+Static arrays have a fixed size, while dynamic arrays can change size during runtime.
+
+---
+
+There is no practical difference in how their sizes are handled.
+
+### --feedback--
+
+Think about how much space each type of array will require.
+
+---
+
+Dynamic arrays are always larger than static arrays.
+
+### --feedback--
+
+Think about how much space each type of array will require.
+
+## --video-solution--
+
+2
+
+## --text--
+
+If you need to add more elements to a static array that is already full, what is the typical process involved?
+
+## --answers--
+
+The static array automatically expands its memory to fit the new elements.
+
+### --feedback--
+
+Think about what is necessary when a container with a fixed capacity runs out of space.
+
+---
+
+You must create a new, larger array and copy all existing elements to it.
+
+---
+
+The array automatically converts itself into a dynamic array.
+
+### --feedback--
+
+Think about what is necessary when a container with a fixed capacity runs out of space.
+
+---
+
+New elements are simply discarded if the array is full.
+
+### --feedback--
+
+Think about what is necessary when a container with a fixed capacity runs out of space.
+
+## --video-solution--
+
+2
+
+## --text--
+
+In which scenario would a static array typically be a more suitable choice than a dynamic array?
+
+## --answers--
+
+When the exact number of elements is unknown and changes frequently.
+
+### --feedback--
+
+Think about the main advantage of a static array related to its size and resource usage.
+
+---
+
+When you need to store a very large dataset that might grow indefinitely.
+
+### --feedback--
+
+Think about the main advantage of a static array related to its size and resource usage.
+
+---
+
+When you require frequent insertions and deletions at arbitrary positions within the collection.
+
+### --feedback--
+
+Think about the main advantage of a static array related to its size and resource usage.
+
+---
+
+When the data size is fixed and known at the time the program is written.
+
+## --video-solution--
+
+4
+
diff --git a/curriculum/challenges/english/25-front-end-development/lecture-working-with-common-data-structures/6895d06b5968736797c408e5.md b/curriculum/challenges/english/25-front-end-development/lecture-working-with-common-data-structures/6895d06b5968736797c408e5.md
new file mode 100644
index 00000000000..e6b3312b9ad
--- /dev/null
+++ b/curriculum/challenges/english/25-front-end-development/lecture-working-with-common-data-structures/6895d06b5968736797c408e5.md
@@ -0,0 +1,195 @@
+---
+id: 6895d06b5968736797c408e5
+title: How Do Stacks and Queues Work?
+challengeType: 19
+dashedName: how-do-stacks-and-queues-work
+---
+
+# --description--
+
+Stacks and queues are data structures commonly used in computer science.
+
+They're linear data structures that follow specific rules for adding and removing elements.
+
+## Stacks
+
+Let's start with **Stacks**.
+
+A **stack** is a Last-in, First-out (LIFO) data structure.
+
+This means that the last element that was added to the stack is the first one to be removed.
+
+Stacks have two ends, which we know as top and bottom.
+
+Elements are added and removed from the top of the stack.
+
+You can think of a stack as a pile of dishes, where you can only place dishes at the top of the pile and take dishes from the top of the pile.
+
+ +
+These operations of adding and removing elements have special names in this context.
+
+Adding an element to a stack is known as a "push" operation. We say that we "push" an element onto the stack when we add it to the top of the stack.
+
+
+
+These operations of adding and removing elements have special names in this context.
+
+Adding an element to a stack is known as a "push" operation. We say that we "push" an element onto the stack when we add it to the top of the stack.
+
+ +
+Removing an element from a stack is known as a "pop" operation. We say that we "pop" an element from the stack when we remove it from the top of the stack.
+
+
+
+Removing an element from a stack is known as a "pop" operation. We say that we "pop" an element from the stack when we remove it from the top of the stack.
+
+ +
+You can see that we don't really perform any operations at the bottom of the stack but we keep it there as a reference.
+
+The time complexity of the push and pop operations is typically `O(1)`, a constant time complexity.
+
+When you push an element onto the stack, the element is simply added to the top.
+
+When you pop an element form the stack, the element at the top is removed.
+
+Therefore, the time it takes to perform these operations remains constant regardless of the size of the stack.
+
+The space complexity of the push and pop operations is usually constant `O(1)`. This means that the amount of memory required to perform these operations remains constant regardless of the size of the stack.
+
+## Queues
+
+Now that you know more about stacks, let's learn about **Queues**.
+
+A queue is a First-in First-out (FIFO) linear data structure. This means that the first element added to the queue is the first one to be removed.
+
+Queues have two ends: front and back.
+
+
+
+You can see that we don't really perform any operations at the bottom of the stack but we keep it there as a reference.
+
+The time complexity of the push and pop operations is typically `O(1)`, a constant time complexity.
+
+When you push an element onto the stack, the element is simply added to the top.
+
+When you pop an element form the stack, the element at the top is removed.
+
+Therefore, the time it takes to perform these operations remains constant regardless of the size of the stack.
+
+The space complexity of the push and pop operations is usually constant `O(1)`. This means that the amount of memory required to perform these operations remains constant regardless of the size of the stack.
+
+## Queues
+
+Now that you know more about stacks, let's learn about **Queues**.
+
+A queue is a First-in First-out (FIFO) linear data structure. This means that the first element added to the queue is the first one to be removed.
+
+Queues have two ends: front and back.
+
+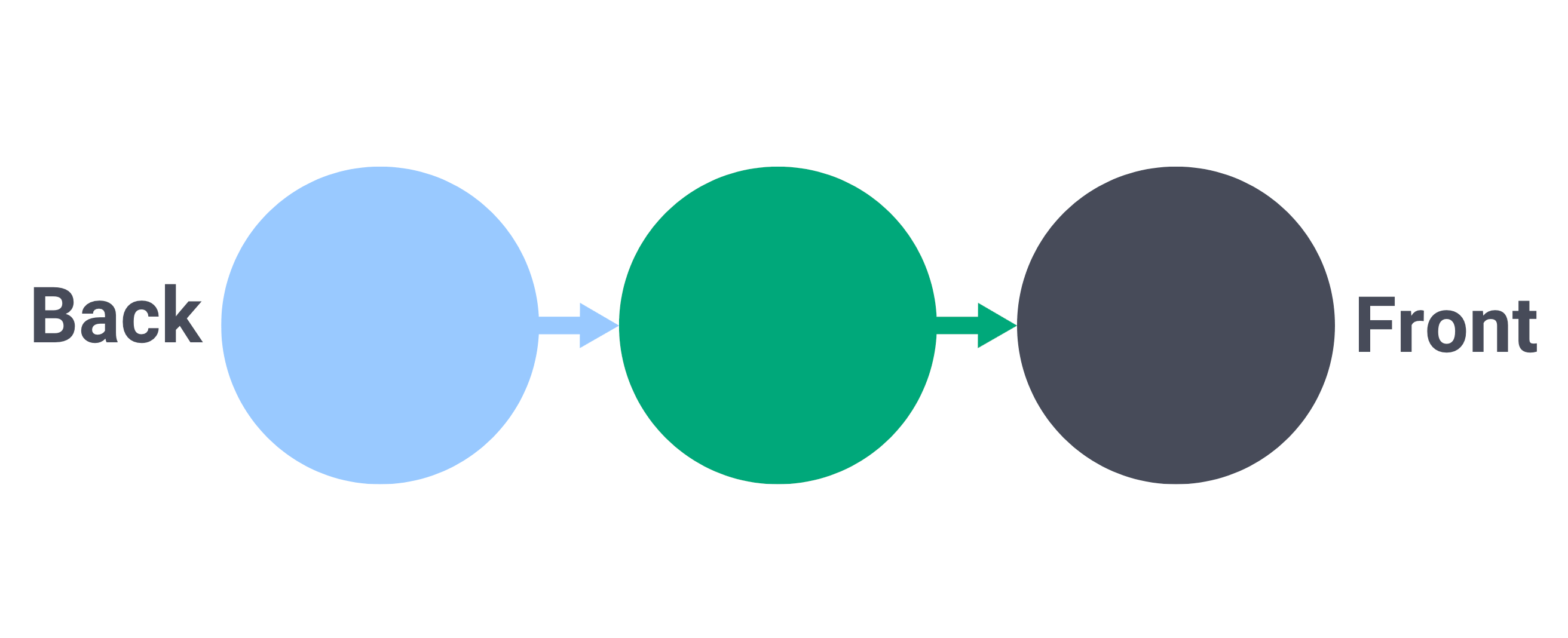 +
+Elements are added to the back of the queue and they are removed from the front of the queue.
+
+You can think of a queue as a line of people waiting to pay for their groceries at the supermarket. The first person in line is the first one to go to the cash register while new people join the line at the end.
+
+The operations of adding and removing elements have special names in the context of a queue.
+
+Adding an element to the back of a queue is known as an "enqueue" operation.
+
+In an enqueue operation, the new element is added to the end of the queue, becoming the end of the line.
+
+
+
+Elements are added to the back of the queue and they are removed from the front of the queue.
+
+You can think of a queue as a line of people waiting to pay for their groceries at the supermarket. The first person in line is the first one to go to the cash register while new people join the line at the end.
+
+The operations of adding and removing elements have special names in the context of a queue.
+
+Adding an element to the back of a queue is known as an "enqueue" operation.
+
+In an enqueue operation, the new element is added to the end of the queue, becoming the end of the line.
+
+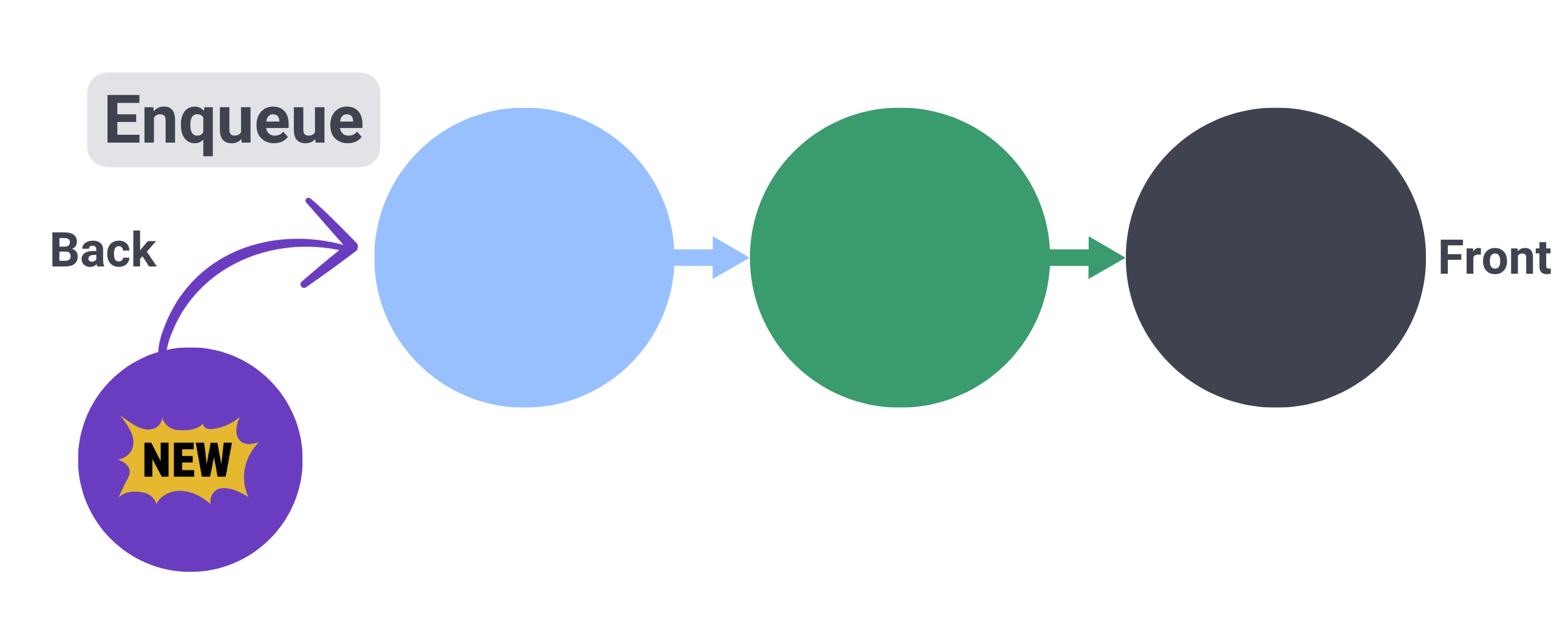 +
+Removing an element from the front of the queue is known as a "dequeue" operation.
+
+In the dequeue operation, the element at the front of the queue is removed, and the next element in line becomes the new front.
+
+
+
+Removing an element from the front of the queue is known as a "dequeue" operation.
+
+In the dequeue operation, the element at the front of the queue is removed, and the next element in line becomes the new front.
+
+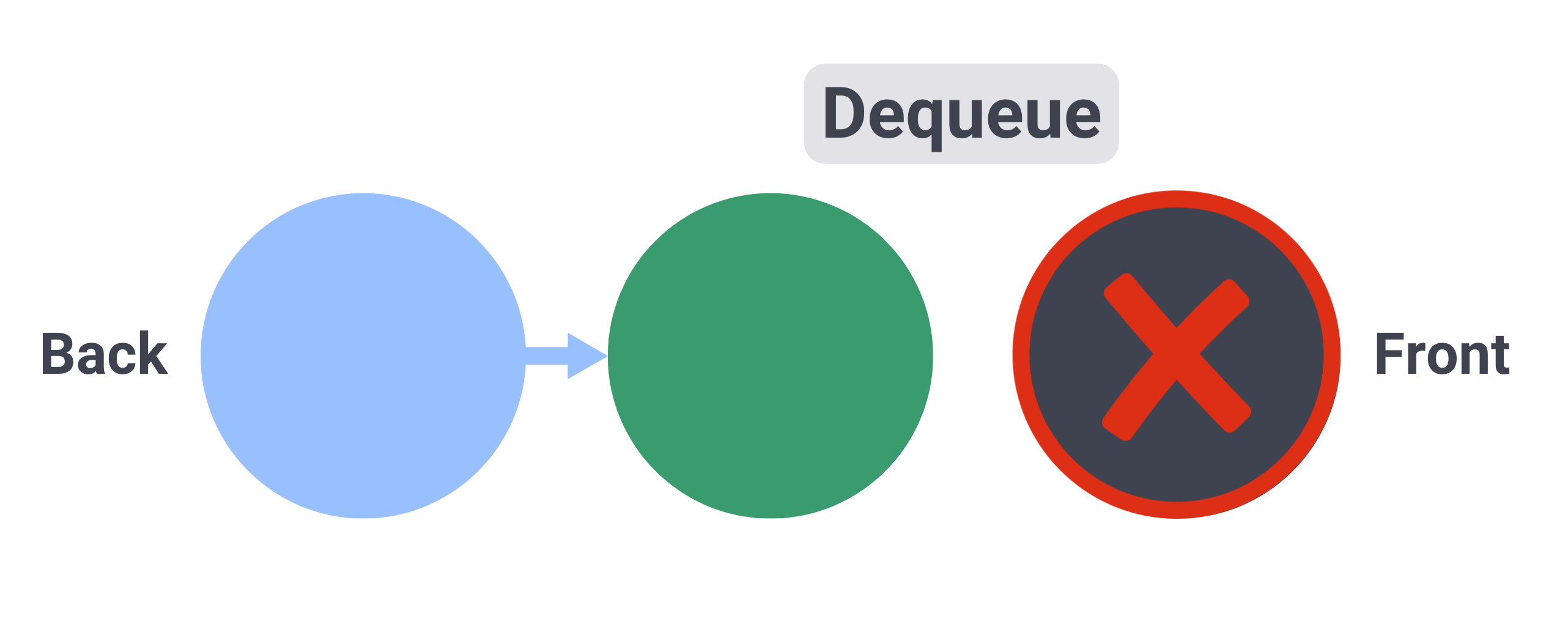 +
+The time complexity of the enqueue and dequeue operations is `O(1)`, constant time. The time it takes to perform these operations remains constant, regardless of the size of the queue.
+
+The space complexity of the enqueue and dequeue operations is usually constant `O(1)`. This means that the amount of memory required to perform these operations remains constant regardless of the size of the queue.
+
+Stacks and queues are data structures used in computer science for organizing and managing elements. Understanding them is essential for building efficient algorithms in various programming applications.
+
+# --questions--
+
+## --text--
+
+What is the primary difference between a stack and a queue?
+
+## --answers--
+
+Stacks are LIFO, while queues are FIFO.
+
+---
+
+Stacks are FIFO, while queues are LIFO.
+
+### --feedback--
+
+Think about the order in which elements are added and removed from each data structure.
+
+---
+
+Stacks are used for storing data, while queues are used for processing data.
+
+### --feedback--
+
+Think about the order in which elements are added and removed from each data structure.
+
+---
+
+There is no difference between stacks and queues.
+
+### --feedback--
+
+Think about the order in which elements are added and removed from each data structure.
+
+## --video-solution--
+
+1
+
+## --text--
+
+Which operation is used to add an element to a stack?
+
+## --answers--
+
+`push`
+
+---
+
+`pop`
+
+### --feedback--
+
+Think about the analogy of a stack of plates.
+
+---
+
+`enqueue`
+
+### --feedback--
+
+Think about the analogy of a stack of plates.
+
+---
+
+`dequeue`
+
+### --feedback--
+
+Think about the analogy of a stack of plates.
+
+## --video-solution--
+
+1
+
+## --text--
+
+Which operation is used to remove an element from a queue?
+
+## --answers--
+
+`push`
+
+### --feedback--
+
+Think about the analogy of a line of people waiting.
+
+---
+
+`pop`
+
+### --feedback--
+
+Think about the analogy of a line of people waiting.
+
+---
+
+`enqueue`
+
+### --feedback--
+
+Think about the analogy of a line of people waiting.
+
+---
+
+`dequeue`
+
+## --video-solution--
+
+4
+
diff --git a/curriculum/challenges/english/25-front-end-development/lecture-working-with-common-data-structures/6895d06b5968736797c408e6.md b/curriculum/challenges/english/25-front-end-development/lecture-working-with-common-data-structures/6895d06b5968736797c408e6.md
new file mode 100644
index 00000000000..e78ec62c3c9
--- /dev/null
+++ b/curriculum/challenges/english/25-front-end-development/lecture-working-with-common-data-structures/6895d06b5968736797c408e6.md
@@ -0,0 +1,231 @@
+---
+id: 6895d06b5968736797c408e6
+title: How Do Singly Linked Lists Work and How Do They Differ From Doubly Linked List?
+challengeType: 19
+dashedName: how-do-singly-linked-lists-work-and-how-do-they-differ-from-doubly-linked-list
+---
+
+# --description--
+
+A **linked list** is a linear data structure in which each node is connected to the next node in the sequence.
+
+These connections create a data structure that looks like a chain of nodes, where each node stores data and a reference to the next node in the linked list.
+
+
+
+The time complexity of the enqueue and dequeue operations is `O(1)`, constant time. The time it takes to perform these operations remains constant, regardless of the size of the queue.
+
+The space complexity of the enqueue and dequeue operations is usually constant `O(1)`. This means that the amount of memory required to perform these operations remains constant regardless of the size of the queue.
+
+Stacks and queues are data structures used in computer science for organizing and managing elements. Understanding them is essential for building efficient algorithms in various programming applications.
+
+# --questions--
+
+## --text--
+
+What is the primary difference between a stack and a queue?
+
+## --answers--
+
+Stacks are LIFO, while queues are FIFO.
+
+---
+
+Stacks are FIFO, while queues are LIFO.
+
+### --feedback--
+
+Think about the order in which elements are added and removed from each data structure.
+
+---
+
+Stacks are used for storing data, while queues are used for processing data.
+
+### --feedback--
+
+Think about the order in which elements are added and removed from each data structure.
+
+---
+
+There is no difference between stacks and queues.
+
+### --feedback--
+
+Think about the order in which elements are added and removed from each data structure.
+
+## --video-solution--
+
+1
+
+## --text--
+
+Which operation is used to add an element to a stack?
+
+## --answers--
+
+`push`
+
+---
+
+`pop`
+
+### --feedback--
+
+Think about the analogy of a stack of plates.
+
+---
+
+`enqueue`
+
+### --feedback--
+
+Think about the analogy of a stack of plates.
+
+---
+
+`dequeue`
+
+### --feedback--
+
+Think about the analogy of a stack of plates.
+
+## --video-solution--
+
+1
+
+## --text--
+
+Which operation is used to remove an element from a queue?
+
+## --answers--
+
+`push`
+
+### --feedback--
+
+Think about the analogy of a line of people waiting.
+
+---
+
+`pop`
+
+### --feedback--
+
+Think about the analogy of a line of people waiting.
+
+---
+
+`enqueue`
+
+### --feedback--
+
+Think about the analogy of a line of people waiting.
+
+---
+
+`dequeue`
+
+## --video-solution--
+
+4
+
diff --git a/curriculum/challenges/english/25-front-end-development/lecture-working-with-common-data-structures/6895d06b5968736797c408e6.md b/curriculum/challenges/english/25-front-end-development/lecture-working-with-common-data-structures/6895d06b5968736797c408e6.md
new file mode 100644
index 00000000000..e78ec62c3c9
--- /dev/null
+++ b/curriculum/challenges/english/25-front-end-development/lecture-working-with-common-data-structures/6895d06b5968736797c408e6.md
@@ -0,0 +1,231 @@
+---
+id: 6895d06b5968736797c408e6
+title: How Do Singly Linked Lists Work and How Do They Differ From Doubly Linked List?
+challengeType: 19
+dashedName: how-do-singly-linked-lists-work-and-how-do-they-differ-from-doubly-linked-list
+---
+
+# --description--
+
+A **linked list** is a linear data structure in which each node is connected to the next node in the sequence.
+
+These connections create a data structure that looks like a chain of nodes, where each node stores data and a reference to the next node in the linked list.
+
+ +
+We use these references to go from the first node to the next node and so on.
+
+Linked lists are commonly used for implementing other data structures, such as stacks, queues, and deques. They can also be used to implement essential graph algorithms, such as depth-first search and breadth-first search.
+
+## Singly Linked Lists
+
+A **singly linked list** is a type of linked list in which each node is connected to the next node in the sequence.
+
+Each node is connected to the next one by storing a reference to it.
+
+This single reference per node allows you to traverse the linked list in one direction, from start to end.
+
+The search can only move forward, not backwards.
+
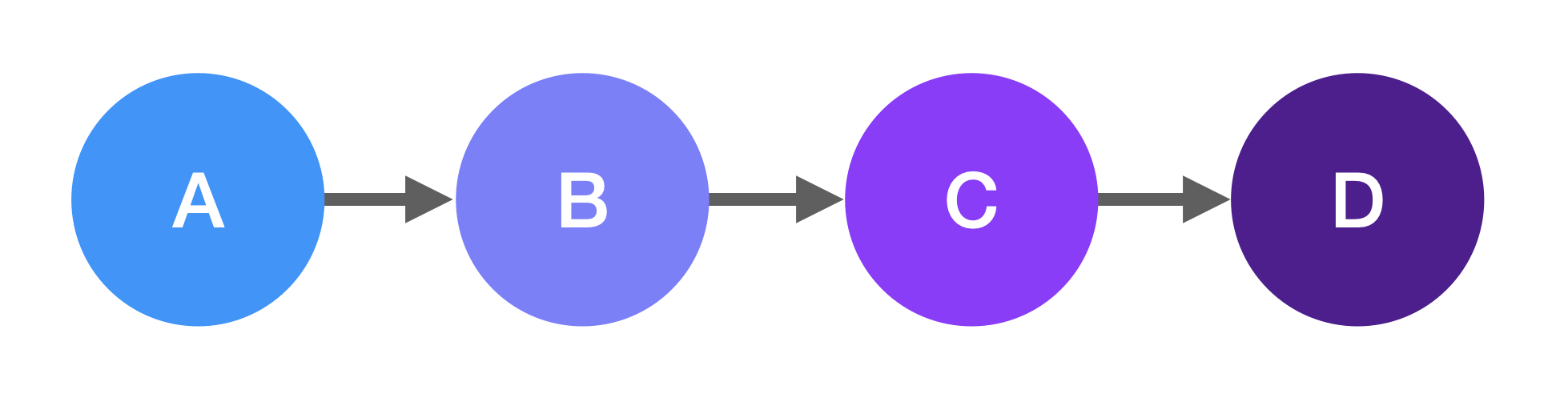
+In this example, you would start at the head node, node A.
+
+The **head** node is the first node in the linked list.
+
+In a singly linked list, the head node is usually the only node that is directly accessible. This is where the search process will start when you're trying to find a specific node.
+
+
+
+We use these references to go from the first node to the next node and so on.
+
+Linked lists are commonly used for implementing other data structures, such as stacks, queues, and deques. They can also be used to implement essential graph algorithms, such as depth-first search and breadth-first search.
+
+## Singly Linked Lists
+
+A **singly linked list** is a type of linked list in which each node is connected to the next node in the sequence.
+
+Each node is connected to the next one by storing a reference to it.
+
+This single reference per node allows you to traverse the linked list in one direction, from start to end.
+
+The search can only move forward, not backwards.
+
+In this example, you would start at the head node, node A.
+
+The **head** node is the first node in the linked list.
+
+In a singly linked list, the head node is usually the only node that is directly accessible. This is where the search process will start when you're trying to find a specific node.
+
+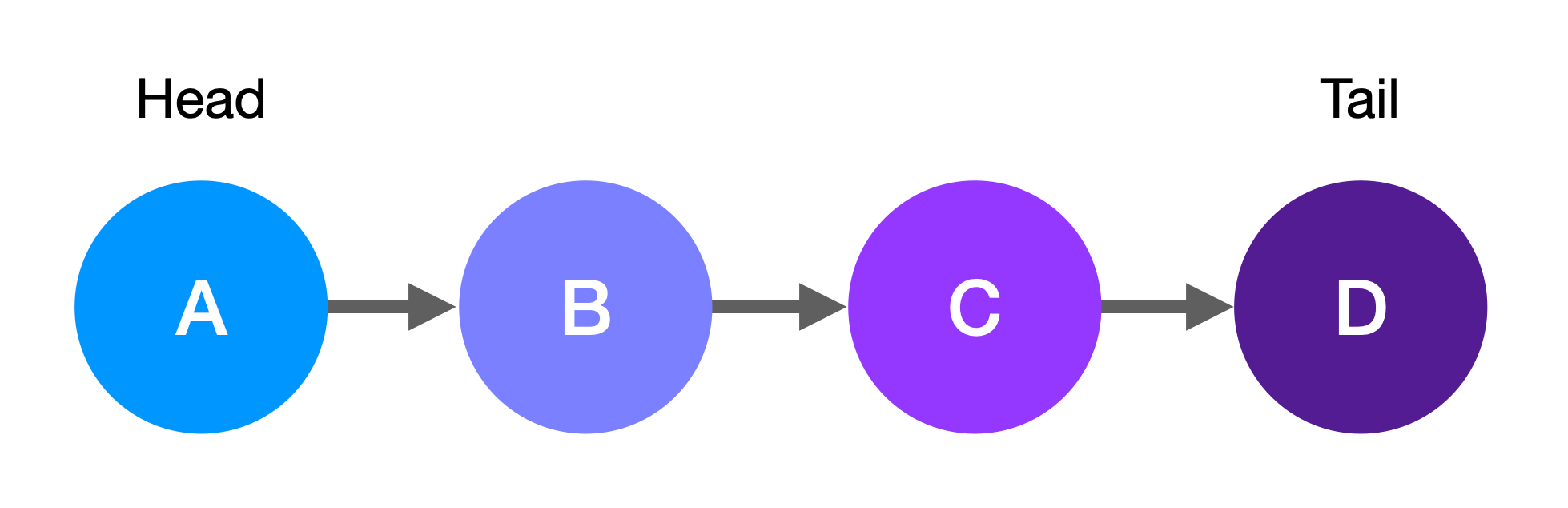 +
+The process will start at node A, then it will continue to node B, then node C, and finally node D, the **tail** node. It may also stop before that if you implement specific logic in your code.
+
+The **tail** node is the last node. It's used to determine when the process has reached the end of the linked list.
+
+### **Inserting Nodes**
+
+One of the great things about linked lists is that they do not have a fixed size. They can be expanded or shrunk as needed by simply updating the connections between the nodes.
+
+You can **insert** a node at the start, middle, and end of a linked list.
+
+Linked lists don't necessarily need to store the nodes in a specific order. The order will be determined by the connections between the nodes.
+
+However, if you do need to keep the nodes in a specific order for your particular use case, you can do so by implementing that logic in your code and the criteria you implement will determine if the node is inserted at the start, middle, or end.
+
+To insert a node at the start of the linked list, you just need to create a connection between the new node and the node that used to be the head node and make the new node the head node instead.
+
+This is an example, where we insert node E at the start and make this new node the head node of the linked list.
+
+
+
+The process will start at node A, then it will continue to node B, then node C, and finally node D, the **tail** node. It may also stop before that if you implement specific logic in your code.
+
+The **tail** node is the last node. It's used to determine when the process has reached the end of the linked list.
+
+### **Inserting Nodes**
+
+One of the great things about linked lists is that they do not have a fixed size. They can be expanded or shrunk as needed by simply updating the connections between the nodes.
+
+You can **insert** a node at the start, middle, and end of a linked list.
+
+Linked lists don't necessarily need to store the nodes in a specific order. The order will be determined by the connections between the nodes.
+
+However, if you do need to keep the nodes in a specific order for your particular use case, you can do so by implementing that logic in your code and the criteria you implement will determine if the node is inserted at the start, middle, or end.
+
+To insert a node at the start of the linked list, you just need to create a connection between the new node and the node that used to be the head node and make the new node the head node instead.
+
+This is an example, where we insert node E at the start and make this new node the head node of the linked list.
+
+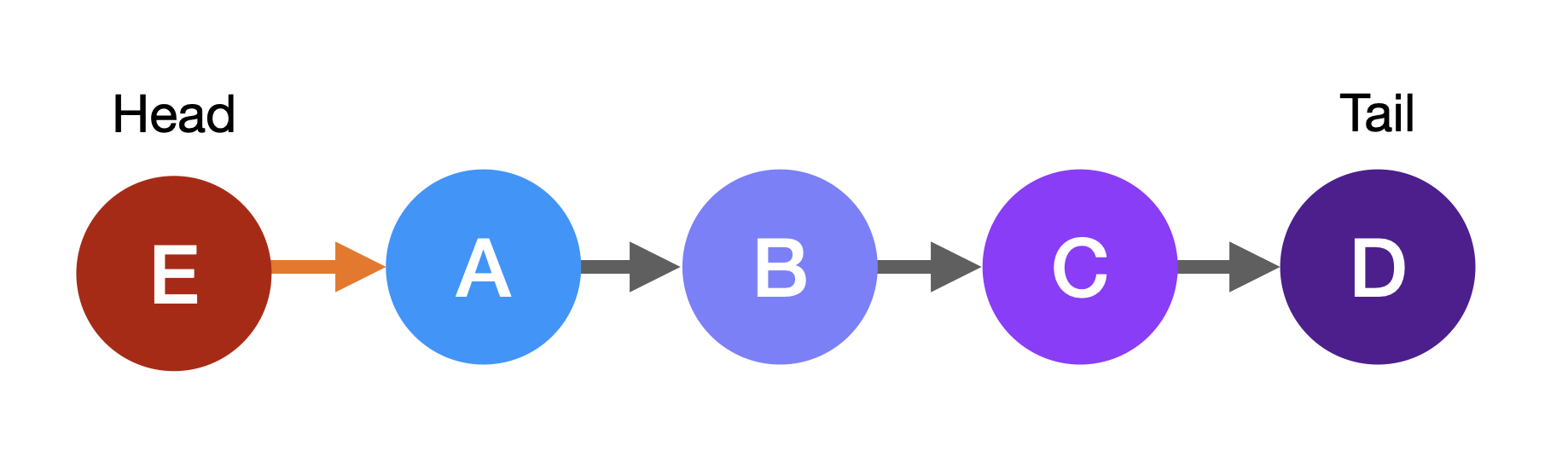 +
+Inserting a node at the beginning of the linked list has a constant time complexity `O(1)` because it only requires updating the reference to the head node and the connection between the new head node and the next node in the sequence.
+
+In this example, we are inserting node E at the start of the linked list. This will work correctly. But if we wanted to keep the linked list sorted in alphabetical order, node E would have to be inserted at the end of the linked list instead.
+
+To insert a node at the end of the linked list, first you need to reach the end and then add a connection to the new node to make it the new tail node.
+
+This operation has linear time complexity, `O(n)`, where n is the number of nodes stored in the linked list, because first you need to reach the end of the linked list to make the insertion and this would require going from one node to the next and so on until the end is reached.
+
+
+
+Inserting a node at the beginning of the linked list has a constant time complexity `O(1)` because it only requires updating the reference to the head node and the connection between the new head node and the next node in the sequence.
+
+In this example, we are inserting node E at the start of the linked list. This will work correctly. But if we wanted to keep the linked list sorted in alphabetical order, node E would have to be inserted at the end of the linked list instead.
+
+To insert a node at the end of the linked list, first you need to reach the end and then add a connection to the new node to make it the new tail node.
+
+This operation has linear time complexity, `O(n)`, where n is the number of nodes stored in the linked list, because first you need to reach the end of the linked list to make the insertion and this would require going from one node to the next and so on until the end is reached.
+
+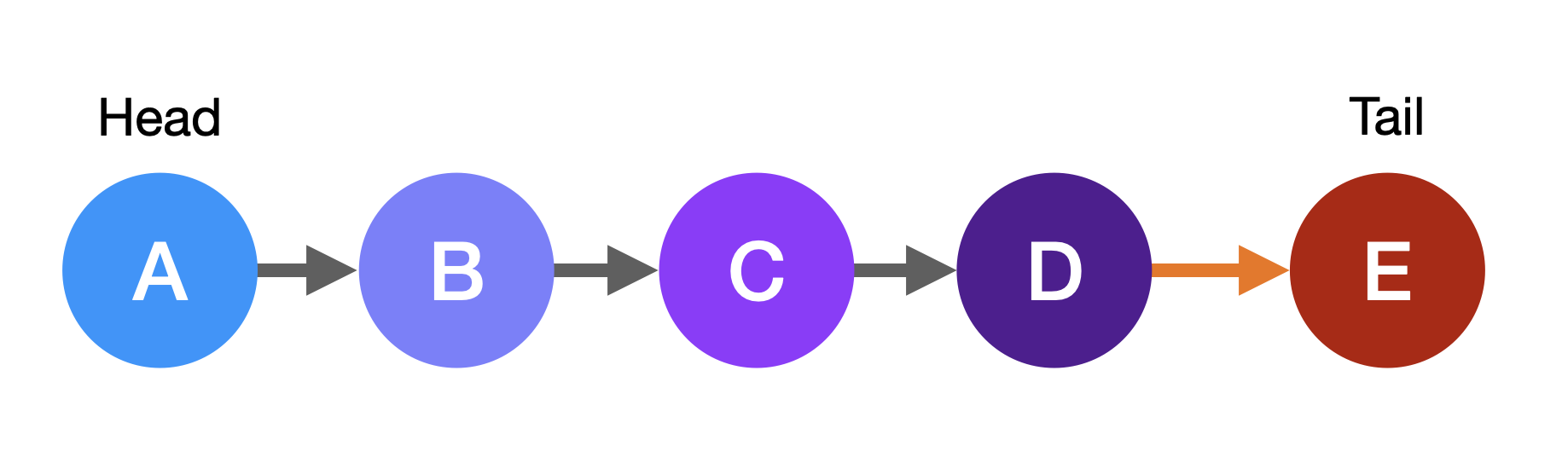 +
+If the node has to be inserted somewhere in the middle of the linked list, the connections between the nodes will have to be updated too. The previous node in the sequence should be connected to the new node and the new node should be connected to the next node, like in the following diagram.
+
+
+
+If the node has to be inserted somewhere in the middle of the linked list, the connections between the nodes will have to be updated too. The previous node in the sequence should be connected to the new node and the new node should be connected to the next node, like in the following diagram.
+
+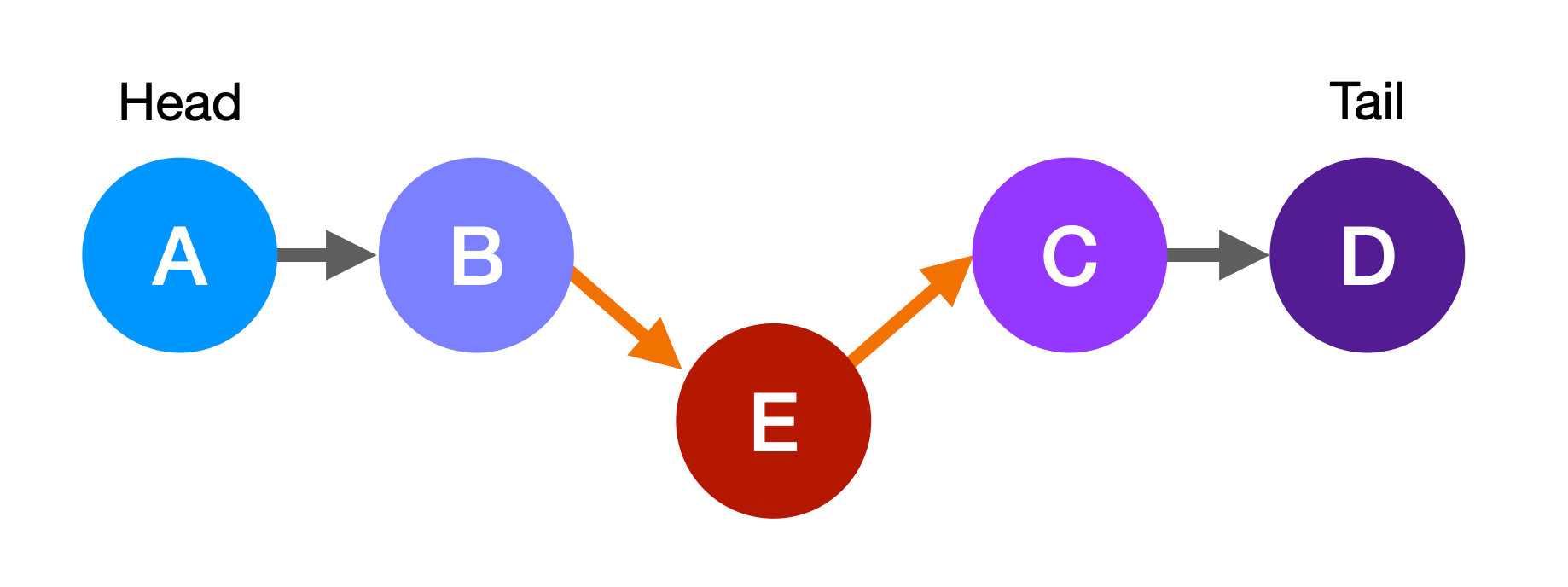 +
+The insertion operation has a constant space complexity `O(1)`, since inserting a new node only requires creating it and updating the connections between the nodes. This operation doesn't depend on the size of the linked list itself.
+
+### **Removing Nodes**
+
+Just as you can insert nodes, you can also remove them from the start, middle, and end of the linked list.
+
+To remove a node from the start, you need to update the reference to the head node, which should be the next node in the sequence.
+
+This operation has a constant time complexity `O(1)`, because it only requires updating the linked list's reference to the head node.
+
+
+
+The insertion operation has a constant space complexity `O(1)`, since inserting a new node only requires creating it and updating the connections between the nodes. This operation doesn't depend on the size of the linked list itself.
+
+### **Removing Nodes**
+
+Just as you can insert nodes, you can also remove them from the start, middle, and end of the linked list.
+
+To remove a node from the start, you need to update the reference to the head node, which should be the next node in the sequence.
+
+This operation has a constant time complexity `O(1)`, because it only requires updating the linked list's reference to the head node.
+
+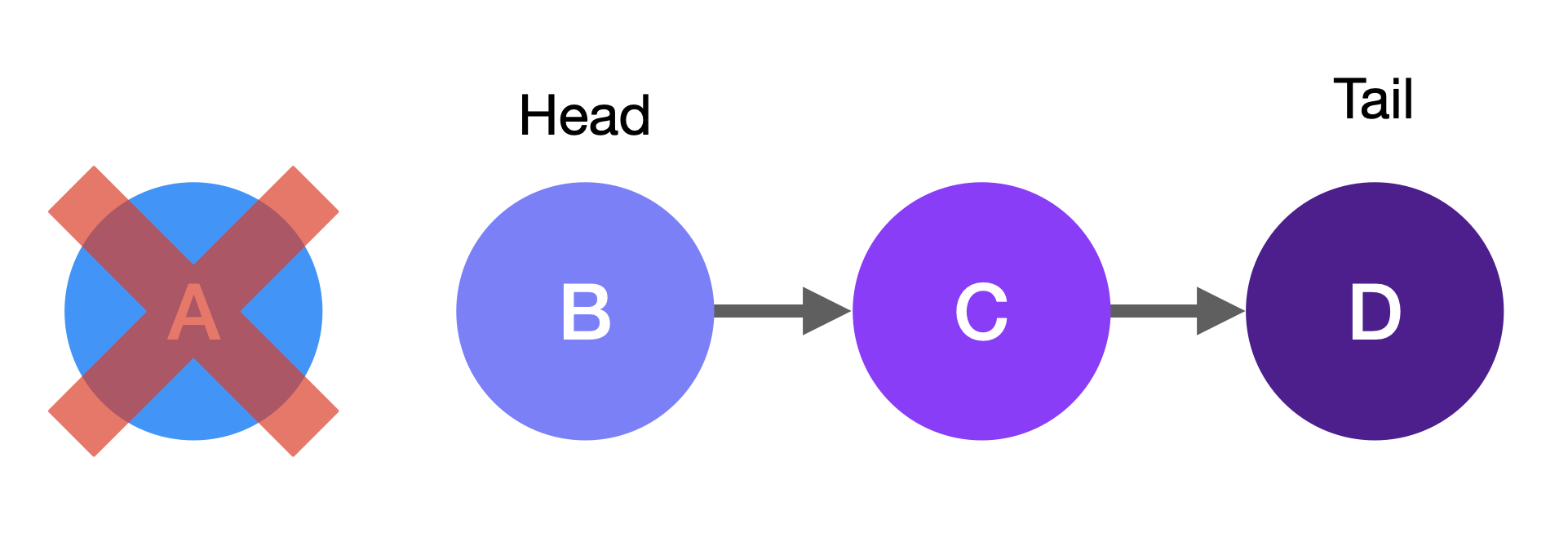 +
+To remove a node from the middle of the linked list, you need to update the reference of the previous node to connect it to the next node in the sequence, forming a sort of "bridge" between them, as you can see in this diagram.
+
+
+
+To remove a node from the middle of the linked list, you need to update the reference of the previous node to connect it to the next node in the sequence, forming a sort of "bridge" between them, as you can see in this diagram.
+
+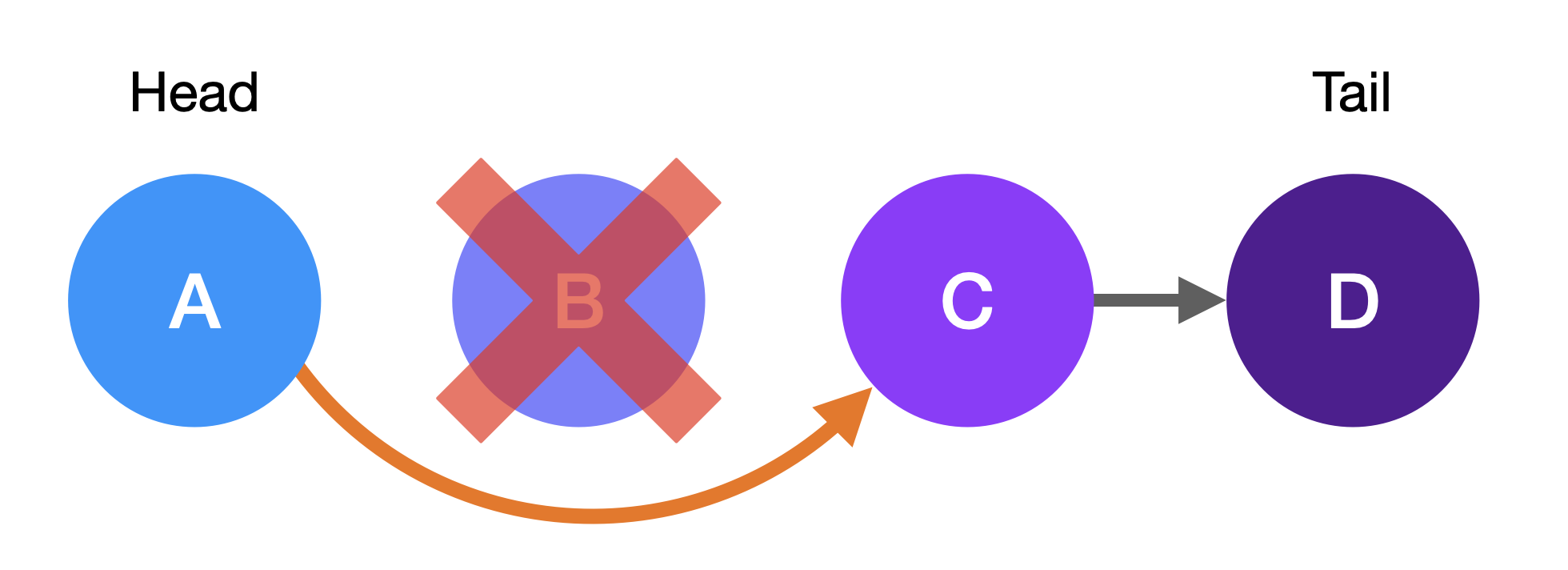 +
+That will remove the node that you want to remove, in this case node B, from the sequence of connections, so it won't be reached the next time you traverse it.
+
+To remove a node from the end of the linked list, you need to remove the connection of the previous node and make this node the new tail node. Now the linked list will end at the new tail node.
+
+This operation has a linear time complexity `O(n)`, because first you have to reach the end of the linked list.
+
+
+
+That will remove the node that you want to remove, in this case node B, from the sequence of connections, so it won't be reached the next time you traverse it.
+
+To remove a node from the end of the linked list, you need to remove the connection of the previous node and make this node the new tail node. Now the linked list will end at the new tail node.
+
+This operation has a linear time complexity `O(n)`, because first you have to reach the end of the linked list.
+
+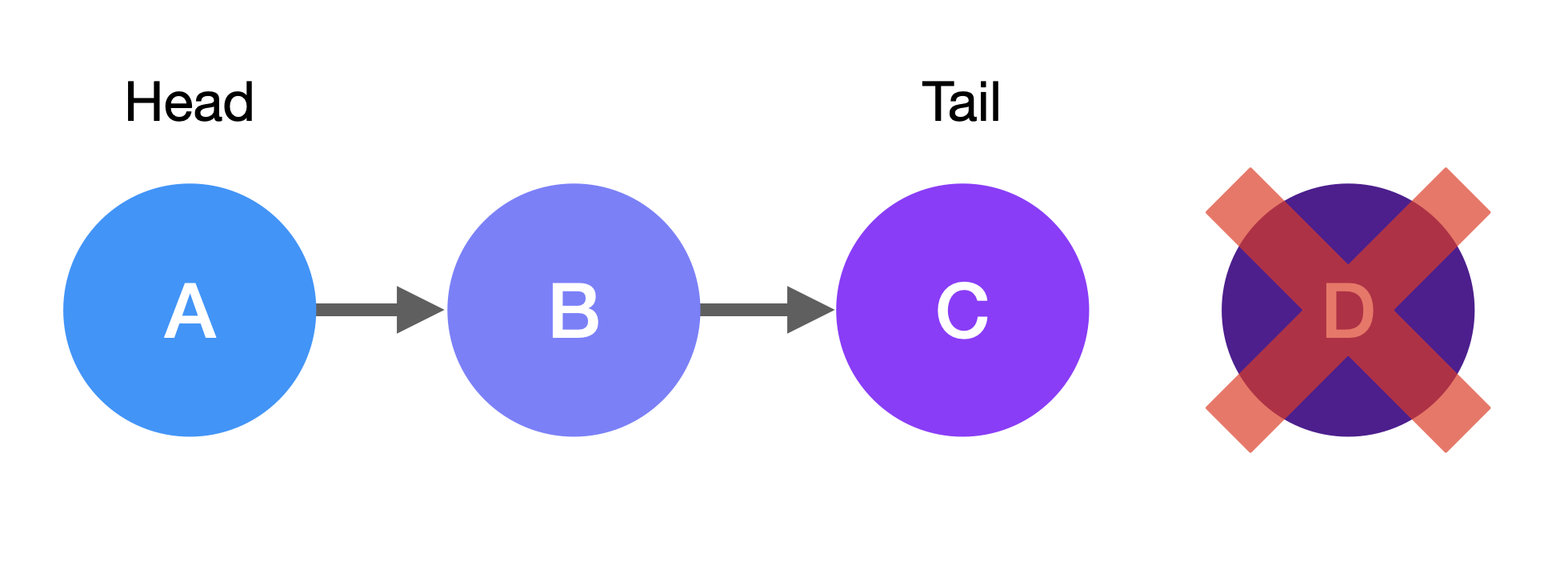 +
+The deletion operation has a constant space complexity `O(1)`, because no additional memory is required to delete a node.
+
+## Doubly Linked Lists
+
+Now that you know more about singly linked lists, let's talk about doubly linked lists.
+
+In a **doubly linked list**, each node stores two references: a reference to the next node and a reference to the previous node in the sequence.
+
+This means that doubly linked lists can be traversed in both directions.
+
+
+
+The deletion operation has a constant space complexity `O(1)`, because no additional memory is required to delete a node.
+
+## Doubly Linked Lists
+
+Now that you know more about singly linked lists, let's talk about doubly linked lists.
+
+In a **doubly linked list**, each node stores two references: a reference to the next node and a reference to the previous node in the sequence.
+
+This means that doubly linked lists can be traversed in both directions.
+
+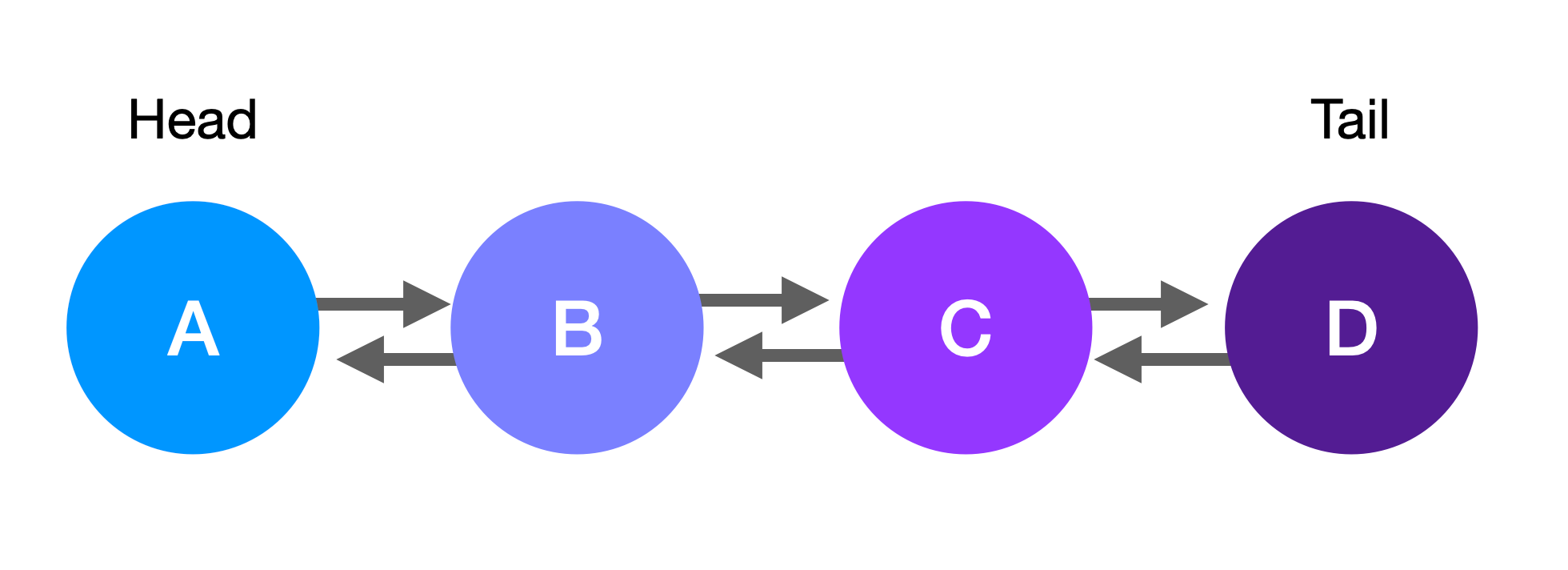 +
+In this type of linked list, it's also common to keep a reference to the tail node in the linked list itself to start the traversal from the end if necessary.
+
+That sounds great, right? They're more flexible than singly linked lists.
+
+However, doubly linked lists do require more memory than singly linked lists because each node stores **two** references instead of one.
+
+This is something that you should keep in mind when you're choosing the right data structure for your project.
+
+There **is** a tradeoff.
+
+The insertion and deletion operations work exactly the same. The only difference is that now you will need to update two references per node and keep track of the reference to the tail node to insert elements at the end of the doubly linked list very efficiently and start the traversal process from the back, if necessary.
+
+Singly and doubly linked lists are essential data structures in computer science used for storing and manipulating elements in a sequential order. Understanding their differences is essential for choosing the right one for your specific application.
+
+# --questions--
+
+## --text--
+
+What is a linked list?
+
+## --answers--
+
+A data structure that stores elements in a contiguous block of memory.
+
+### --feedback--
+
+Think about how nodes are connected in a linked list.
+
+---
+
+A data structure where nodes are connected using references.
+
+---
+
+A data structure that is always sorted.
+
+### --feedback--
+
+Think about how nodes are connected in a linked list.
+
+---
+
+A data structure that has a fixed size.
+
+### --feedback--
+
+Think about how nodes are connected in a linked list.
+
+## --video-solution--
+
+2
+
+## --text--
+
+What is the difference between a singly linked list and a doubly linked list?
+
+## --answers--
+
+Singly linked lists have a head and tail node, while doubly linked lists do not.
+
+### --feedback--
+
+Think about the references contained in each type of linked list.
+
+---
+
+Singly linked lists can only be traversed in one direction, while doubly linked lists can be traversed in both directions.
+
+---
+
+Singly linked lists are more efficient to insert elements at the end, while doubly linked lists are more efficient to insert elements at the beginning.
+
+### --feedback--
+
+Think about the references contained in each type of linked list.
+
+---
+
+Singly linked lists require more memory than doubly linked lists.
+
+### --feedback--
+
+Think about the references contained in each type of linked list.
+
+## --video-solution--
+
+2
+
+## --text--
+
+What is the time complexity of inserting a node at the beginning of a singly linked list?
+
+## --answers--
+
+`O(1)`
+
+---
+
+`O(n)`
+
+### --feedback--
+
+Think about the number of operations required to insert a node at the beginning of the linked list.
+
+---
+
+`O(n^2)`
+
+### --feedback--
+
+Think about the number of operations required to insert a node at the beginning of the linked list.
+
+---
+
+`O(log n)`
+
+### --feedback--
+
+Think about the number of operations required to insert a node at the beginning of the linked list.
+
+## --video-solution--
+
+1
+
diff --git a/curriculum/challenges/english/25-front-end-development/lecture-working-with-common-data-structures/6895d06b5968736797c408e7.md b/curriculum/challenges/english/25-front-end-development/lecture-working-with-common-data-structures/6895d06b5968736797c408e7.md
new file mode 100644
index 00000000000..c60c8450300
--- /dev/null
+++ b/curriculum/challenges/english/25-front-end-development/lecture-working-with-common-data-structures/6895d06b5968736797c408e7.md
@@ -0,0 +1,317 @@
+---
+id: 6895d06b5968736797c408e7
+title: How Do Maps, Hash Maps and Sets Work?
+challengeType: 19
+dashedName: how-do-maps-hash-maps-and-sets-work
+---
+
+# --description--
+
+In this lecture, we'll go over maps, hash maps, and sets. But before we do that, let's define Abstract Data Types.
+
+An Abstract Data Type (ADT) is a conceptual representation of a data type, including what operations can be performed on the data and the properties of that data.
+
+Abstract Data Types are like blueprints that describe **what** operations can be performed, not **how** they are performed. They separate the interface from the actual implementation of the operations.
+
+A **map** is an ADT that manages collections of key-value pairs and their operations in a very specific and efficient way.
+
+In a map, every value is associated with a specific key.
+
+One of the key characteristics of maps is that every key must be unique. This uniqueness allows for direct lookups, which makes the process of retrieving information much more efficient.
+
+Only keys must be unique, values can be repeated.
+
+The map Abstract Data Type also defines important operations, such as inserting key-value pairs, getting the value associated with a key, updating the value associated with a key, removing a key-value pair, and checking if a key exists in the map.
+
+It doesn't actually specify how these operations should be performed, it just lists them as part of the available operations of the data type.
+
+A **hash map**, also known as a hash table, is a concrete implementation of the map Abstract Data Type.
+
+Hash maps use a technique called "hashing" to perform common operations very efficiently.
+
+Hashing essentially works by generating a hash value for each element using a hash function.
+
+The hash value is generated based on the key of the key-value pair and it's used to calculate an index in an underlying array, the actual data structure where the key-value pairs are stored.
+
+But you might be asking yourself: What happens if two keys result in the same index?
+
+Hash maps solve these collisions with clever strategies.
+
+One option is to use the "chaining" strategy, where each array index points to a linked list (another data structure), where all the elements with the same index are stored.
+
+Another strategy is to use "open addressing", which involves searching for the next available index in the array based on a predefined search sequence.
+
+The average case time complexity of hash maps is "Constant Time" `O(1)` for inserting, retrieving, and deleting key-value pairs.
+
+The worst case time complexity of these operations is Linear Time `O(n)`, which occurs when there are many hash collisions, so the collision resolution strategy has to be applied multiple times.
+
+The space complexity of inserting into a hash map is constant `O(1)` on the average case, a constant amount of memory to store the new pair. However, in the worst case, it can have linear space complexity `O(n)` due to a resizing operation of the underlying array. In general, removing an element has a constant space complexity `O(1)`.
+
+This turns the hash table into something similar to a linear data structure where `n` elements have to be scanned to find the target key. However, this is relatively rare if the hash map is implemented properly.
+
+Python's **dictionaries** are implemented as hash maps behind the scenes.
+
+To create a Python dictionary, you just need to write the key-value pairs within curly brackets and separate them with a comma. Each key should be separated from its corresponding value with a colon.
+
+```python
+my_dictionary = {
+ "A": 1,
+ "B": 2,
+ "C": 3
+}
+```
+
+In this code, `"A"` is the key and `1` is the value:
+
+```python
+"A": 1
+```
+
+Alternatively, you can use `dict()`:
+
+```python
+my_dictionary = dict(A="1", B="2", C="3")
+```
+
+You can get the value through its corresponding key:
+
+```python
+my_dictionary["A"] # 1
+```
+
+You can also update the value associated with a key:
+
+```python
+my_dictionary["A"] = 4
+```
+
+And you can remove a key-value pair:
+
+```python
+del my_dictionary["A"]
+```
+
+You can also check if a key is in the dictionary (or not):
+
+```python
+"C" in my_dictionary
+```
+
+And you can call these methods to get the keys, values, and items of the dictionary, respectively.
+
+```python
+my_dictionary.keys()
+my_dictionary.values()
+my_dictionary.items()
+```
+
+Great. Now that you know more about maps and hash maps, let's talk about sets.
+
+**Sets** are unordered collections of unique elements.
+
+Let's break this concept down into its key components:
+
+* Sets are unordered. The elements of a set are not stored in any specific order, so you cannot access them through indices.
+
+* Sets only contain unique elements. If you try to add the same value twice, only one copy of the value will be kept.
+
+
+They are analogous to sets in mathematics and they implement the same set operations, like intersection, union, and difference.
+
+One of the main advantages of sets is that they guarantee that the elements will be unique (no duplicates). This is why they are often used to remove duplicates from lists and other data structures.
+
+They are also dynamic. They can adjust to the number of elements that are currently stored. This makes them quite powerful.
+
+The average case time complexity of adding, removing, getting the length of the set, and checking if an element is in the set is "Constant Time" `O(1)`, which is very efficient.
+
+Since sets are implemented as hash tables, the worst case time complexity of adding, removing, and checking membership is "Linear Time" `O(n)`. This may occur when there are multiple hash collisions, transforming the hash table into something similar to a linear data structure, where `n` scans are required to find the key.
+
+In terms of space complexity, in the average case, inserting an element would have constant complexity `O(1)`, with a new unique element requiring a constant amount of memory. However, in the worst case, there could be a resizing operation of the underlying array, which could take linear space complexity `O(n)`. In general, removing an element would take constant space complexity `O(1)`.
+
+Python has a built-in `set` data structure that you use to work with sets in your programs.
+
+Behind the scenes, Python sets are implemented using a hash table where only the keys are stored, without any associated values.
+
+Sets can only store objects of immutable data types because their hash values always remain the same. In contrast, the hash values of mutable objects can change when they are mutated. That's why they cannot be part of sets. If the hash value of an object stored in the set changes, the program would not be able to find it anymore.
+
+To define a set in Python, you just need to surround the elements with curly brackets and separate them with commas:
+
+```python
+numbers = {1, 2, 3, 4}
+```
+
+To create an empty set, you can call `set()`:
+
+```python
+numbers = set()
+```
+
+Note that if you use empty curly brackets, this will automatically create a Python dictionary, not a set, so you must call the `set()` function to create an empty set.
+
+You can add an element to a set with the `.add()` method:
+
+```python
+numbers.add(5)
+```
+
+You can also remove elements from the set with the `.remove()` method:
+
+```python
+numbers.remove(5)
+```
+
+This will throw a `KeyError` if the element is not found. But if you don't want to throw an error in that case, you can use the `.discard()` method instead.
+
+The `.pop()` method returns an arbitrary element from the set, while the `.clear()` method removes all elements from the set.
+
+You can test if an element is in a set with the `in` operator:
+
+```python
+5 in numbers
+```
+
+Python also support set operations, including union, difference, symmetric difference, and intersection, which you can perform with these methods:
+
+```python
+set_a = {1, 2, 3, 4}
+set_b = {2, 3, 4, 5, 6}
+
+set_a.union(set_b)
+set_a.intersection(set_b)
+set_a.symmetric_difference(set_b)
+set_a.difference(set_b)
+```
+
+Or with their equivalent operators:
+
+```python
+set_a | set_b
+set_a & set_b
+set_a ^ set_b
+set_a - set_b
+```
+
+The average case time complexity for adding, removing, and testing membership is "Constant Time" `O(1)`.
+
+The worst case time complexity for these operations is "Linear Time" `O(n)` because of the hash map's worst case collision scenario.
+
+You can also check if a set is a subset or superset of another one:
+
+```python
+set_a.issubset(set_b)
+set_a.issuperset(set_b)
+```
+
+In general, you should use sets when you need to store a collection of unique items and frequently check for the presence of an item.
+
+Maps, hash maps, and sets are powerful data structures designed for efficient data organization and retrieval. Each one of them has its own unique characteristics and use cases. As a developer, you will need to choose the best one for your project.
+
+# --questions--
+
+## --text--
+
+What is the fundamental difference in the type of data stored by a hash map (or map) compared to a set?
+
+## --answers--
+
+Hash maps store ordered collections, while Sets store unordered collections.
+
+### --feedback--
+
+Think about what each data structure is primarily designed to store.
+
+---
+
+Hash maps store unique key-value pairs, while Sets store unique individual elements.
+
+---
+
+Hash maps cannot store duplicate values, while Sets can.
+
+### --feedback--
+
+Think about what each data structure is primarily designed to store.
+
+---
+
+Sets are used for numerical data, while hash maps are for textual data.
+
+### --feedback--
+
+Think about what each data structure is primarily designed to store.
+
+## --video-solution--
+
+2
+
+## --text--
+
+What is the main mechanism that allows hash maps and Sets to achieve average-case `O(1)` (constant time) performance for operations like insertion and lookup?
+
+## --answers--
+
+They keep all elements sorted, enabling fast binary search.
+
+### --feedback--
+
+Think about the special function that converts an element into an index.
+
+---
+
+They store elements in a linked list, allowing quick traversal.
+
+### --feedback--
+
+Think about the special function that converts an element into an index.
+
+---
+
+They use a hash function to compute a direct memory location for elements.
+
+---
+
+They always store a very small number of elements, making all operations fast.
+
+### --feedback--
+
+Think about the special function that converts an element into an index.
+
+## --video-solution--
+
+3
+
+## --text--
+
+In the context of hash maps and sets, what is a "hash collision"?
+
+## --answers--
+
+When an element is successfully found after a search.
+
+### --feedback--
+
+Think about the result when the hash function maps different inputs to the same output.
+
+---
+
+When an element is inserted at the very beginning of the collection.
+
+### --feedback--
+
+Think about the result when the hash function maps different inputs to the same output.
+
+---
+
+When the hash map runs out of memory and needs to resize.
+
+### --feedback--
+
+Think about the result when the hash function maps different inputs to the same output.
+
+---
+
+When two different keys or elements produce the same hash value.
+
+## --video-solution--
+
+4
+
+In this type of linked list, it's also common to keep a reference to the tail node in the linked list itself to start the traversal from the end if necessary.
+
+That sounds great, right? They're more flexible than singly linked lists.
+
+However, doubly linked lists do require more memory than singly linked lists because each node stores **two** references instead of one.
+
+This is something that you should keep in mind when you're choosing the right data structure for your project.
+
+There **is** a tradeoff.
+
+The insertion and deletion operations work exactly the same. The only difference is that now you will need to update two references per node and keep track of the reference to the tail node to insert elements at the end of the doubly linked list very efficiently and start the traversal process from the back, if necessary.
+
+Singly and doubly linked lists are essential data structures in computer science used for storing and manipulating elements in a sequential order. Understanding their differences is essential for choosing the right one for your specific application.
+
+# --questions--
+
+## --text--
+
+What is a linked list?
+
+## --answers--
+
+A data structure that stores elements in a contiguous block of memory.
+
+### --feedback--
+
+Think about how nodes are connected in a linked list.
+
+---
+
+A data structure where nodes are connected using references.
+
+---
+
+A data structure that is always sorted.
+
+### --feedback--
+
+Think about how nodes are connected in a linked list.
+
+---
+
+A data structure that has a fixed size.
+
+### --feedback--
+
+Think about how nodes are connected in a linked list.
+
+## --video-solution--
+
+2
+
+## --text--
+
+What is the difference between a singly linked list and a doubly linked list?
+
+## --answers--
+
+Singly linked lists have a head and tail node, while doubly linked lists do not.
+
+### --feedback--
+
+Think about the references contained in each type of linked list.
+
+---
+
+Singly linked lists can only be traversed in one direction, while doubly linked lists can be traversed in both directions.
+
+---
+
+Singly linked lists are more efficient to insert elements at the end, while doubly linked lists are more efficient to insert elements at the beginning.
+
+### --feedback--
+
+Think about the references contained in each type of linked list.
+
+---
+
+Singly linked lists require more memory than doubly linked lists.
+
+### --feedback--
+
+Think about the references contained in each type of linked list.
+
+## --video-solution--
+
+2
+
+## --text--
+
+What is the time complexity of inserting a node at the beginning of a singly linked list?
+
+## --answers--
+
+`O(1)`
+
+---
+
+`O(n)`
+
+### --feedback--
+
+Think about the number of operations required to insert a node at the beginning of the linked list.
+
+---
+
+`O(n^2)`
+
+### --feedback--
+
+Think about the number of operations required to insert a node at the beginning of the linked list.
+
+---
+
+`O(log n)`
+
+### --feedback--
+
+Think about the number of operations required to insert a node at the beginning of the linked list.
+
+## --video-solution--
+
+1
+
diff --git a/curriculum/challenges/english/25-front-end-development/lecture-working-with-common-data-structures/6895d06b5968736797c408e7.md b/curriculum/challenges/english/25-front-end-development/lecture-working-with-common-data-structures/6895d06b5968736797c408e7.md
new file mode 100644
index 00000000000..c60c8450300
--- /dev/null
+++ b/curriculum/challenges/english/25-front-end-development/lecture-working-with-common-data-structures/6895d06b5968736797c408e7.md
@@ -0,0 +1,317 @@
+---
+id: 6895d06b5968736797c408e7
+title: How Do Maps, Hash Maps and Sets Work?
+challengeType: 19
+dashedName: how-do-maps-hash-maps-and-sets-work
+---
+
+# --description--
+
+In this lecture, we'll go over maps, hash maps, and sets. But before we do that, let's define Abstract Data Types.
+
+An Abstract Data Type (ADT) is a conceptual representation of a data type, including what operations can be performed on the data and the properties of that data.
+
+Abstract Data Types are like blueprints that describe **what** operations can be performed, not **how** they are performed. They separate the interface from the actual implementation of the operations.
+
+A **map** is an ADT that manages collections of key-value pairs and their operations in a very specific and efficient way.
+
+In a map, every value is associated with a specific key.
+
+One of the key characteristics of maps is that every key must be unique. This uniqueness allows for direct lookups, which makes the process of retrieving information much more efficient.
+
+Only keys must be unique, values can be repeated.
+
+The map Abstract Data Type also defines important operations, such as inserting key-value pairs, getting the value associated with a key, updating the value associated with a key, removing a key-value pair, and checking if a key exists in the map.
+
+It doesn't actually specify how these operations should be performed, it just lists them as part of the available operations of the data type.
+
+A **hash map**, also known as a hash table, is a concrete implementation of the map Abstract Data Type.
+
+Hash maps use a technique called "hashing" to perform common operations very efficiently.
+
+Hashing essentially works by generating a hash value for each element using a hash function.
+
+The hash value is generated based on the key of the key-value pair and it's used to calculate an index in an underlying array, the actual data structure where the key-value pairs are stored.
+
+But you might be asking yourself: What happens if two keys result in the same index?
+
+Hash maps solve these collisions with clever strategies.
+
+One option is to use the "chaining" strategy, where each array index points to a linked list (another data structure), where all the elements with the same index are stored.
+
+Another strategy is to use "open addressing", which involves searching for the next available index in the array based on a predefined search sequence.
+
+The average case time complexity of hash maps is "Constant Time" `O(1)` for inserting, retrieving, and deleting key-value pairs.
+
+The worst case time complexity of these operations is Linear Time `O(n)`, which occurs when there are many hash collisions, so the collision resolution strategy has to be applied multiple times.
+
+The space complexity of inserting into a hash map is constant `O(1)` on the average case, a constant amount of memory to store the new pair. However, in the worst case, it can have linear space complexity `O(n)` due to a resizing operation of the underlying array. In general, removing an element has a constant space complexity `O(1)`.
+
+This turns the hash table into something similar to a linear data structure where `n` elements have to be scanned to find the target key. However, this is relatively rare if the hash map is implemented properly.
+
+Python's **dictionaries** are implemented as hash maps behind the scenes.
+
+To create a Python dictionary, you just need to write the key-value pairs within curly brackets and separate them with a comma. Each key should be separated from its corresponding value with a colon.
+
+```python
+my_dictionary = {
+ "A": 1,
+ "B": 2,
+ "C": 3
+}
+```
+
+In this code, `"A"` is the key and `1` is the value:
+
+```python
+"A": 1
+```
+
+Alternatively, you can use `dict()`:
+
+```python
+my_dictionary = dict(A="1", B="2", C="3")
+```
+
+You can get the value through its corresponding key:
+
+```python
+my_dictionary["A"] # 1
+```
+
+You can also update the value associated with a key:
+
+```python
+my_dictionary["A"] = 4
+```
+
+And you can remove a key-value pair:
+
+```python
+del my_dictionary["A"]
+```
+
+You can also check if a key is in the dictionary (or not):
+
+```python
+"C" in my_dictionary
+```
+
+And you can call these methods to get the keys, values, and items of the dictionary, respectively.
+
+```python
+my_dictionary.keys()
+my_dictionary.values()
+my_dictionary.items()
+```
+
+Great. Now that you know more about maps and hash maps, let's talk about sets.
+
+**Sets** are unordered collections of unique elements.
+
+Let's break this concept down into its key components:
+
+* Sets are unordered. The elements of a set are not stored in any specific order, so you cannot access them through indices.
+
+* Sets only contain unique elements. If you try to add the same value twice, only one copy of the value will be kept.
+
+
+They are analogous to sets in mathematics and they implement the same set operations, like intersection, union, and difference.
+
+One of the main advantages of sets is that they guarantee that the elements will be unique (no duplicates). This is why they are often used to remove duplicates from lists and other data structures.
+
+They are also dynamic. They can adjust to the number of elements that are currently stored. This makes them quite powerful.
+
+The average case time complexity of adding, removing, getting the length of the set, and checking if an element is in the set is "Constant Time" `O(1)`, which is very efficient.
+
+Since sets are implemented as hash tables, the worst case time complexity of adding, removing, and checking membership is "Linear Time" `O(n)`. This may occur when there are multiple hash collisions, transforming the hash table into something similar to a linear data structure, where `n` scans are required to find the key.
+
+In terms of space complexity, in the average case, inserting an element would have constant complexity `O(1)`, with a new unique element requiring a constant amount of memory. However, in the worst case, there could be a resizing operation of the underlying array, which could take linear space complexity `O(n)`. In general, removing an element would take constant space complexity `O(1)`.
+
+Python has a built-in `set` data structure that you use to work with sets in your programs.
+
+Behind the scenes, Python sets are implemented using a hash table where only the keys are stored, without any associated values.
+
+Sets can only store objects of immutable data types because their hash values always remain the same. In contrast, the hash values of mutable objects can change when they are mutated. That's why they cannot be part of sets. If the hash value of an object stored in the set changes, the program would not be able to find it anymore.
+
+To define a set in Python, you just need to surround the elements with curly brackets and separate them with commas:
+
+```python
+numbers = {1, 2, 3, 4}
+```
+
+To create an empty set, you can call `set()`:
+
+```python
+numbers = set()
+```
+
+Note that if you use empty curly brackets, this will automatically create a Python dictionary, not a set, so you must call the `set()` function to create an empty set.
+
+You can add an element to a set with the `.add()` method:
+
+```python
+numbers.add(5)
+```
+
+You can also remove elements from the set with the `.remove()` method:
+
+```python
+numbers.remove(5)
+```
+
+This will throw a `KeyError` if the element is not found. But if you don't want to throw an error in that case, you can use the `.discard()` method instead.
+
+The `.pop()` method returns an arbitrary element from the set, while the `.clear()` method removes all elements from the set.
+
+You can test if an element is in a set with the `in` operator:
+
+```python
+5 in numbers
+```
+
+Python also support set operations, including union, difference, symmetric difference, and intersection, which you can perform with these methods:
+
+```python
+set_a = {1, 2, 3, 4}
+set_b = {2, 3, 4, 5, 6}
+
+set_a.union(set_b)
+set_a.intersection(set_b)
+set_a.symmetric_difference(set_b)
+set_a.difference(set_b)
+```
+
+Or with their equivalent operators:
+
+```python
+set_a | set_b
+set_a & set_b
+set_a ^ set_b
+set_a - set_b
+```
+
+The average case time complexity for adding, removing, and testing membership is "Constant Time" `O(1)`.
+
+The worst case time complexity for these operations is "Linear Time" `O(n)` because of the hash map's worst case collision scenario.
+
+You can also check if a set is a subset or superset of another one:
+
+```python
+set_a.issubset(set_b)
+set_a.issuperset(set_b)
+```
+
+In general, you should use sets when you need to store a collection of unique items and frequently check for the presence of an item.
+
+Maps, hash maps, and sets are powerful data structures designed for efficient data organization and retrieval. Each one of them has its own unique characteristics and use cases. As a developer, you will need to choose the best one for your project.
+
+# --questions--
+
+## --text--
+
+What is the fundamental difference in the type of data stored by a hash map (or map) compared to a set?
+
+## --answers--
+
+Hash maps store ordered collections, while Sets store unordered collections.
+
+### --feedback--
+
+Think about what each data structure is primarily designed to store.
+
+---
+
+Hash maps store unique key-value pairs, while Sets store unique individual elements.
+
+---
+
+Hash maps cannot store duplicate values, while Sets can.
+
+### --feedback--
+
+Think about what each data structure is primarily designed to store.
+
+---
+
+Sets are used for numerical data, while hash maps are for textual data.
+
+### --feedback--
+
+Think about what each data structure is primarily designed to store.
+
+## --video-solution--
+
+2
+
+## --text--
+
+What is the main mechanism that allows hash maps and Sets to achieve average-case `O(1)` (constant time) performance for operations like insertion and lookup?
+
+## --answers--
+
+They keep all elements sorted, enabling fast binary search.
+
+### --feedback--
+
+Think about the special function that converts an element into an index.
+
+---
+
+They store elements in a linked list, allowing quick traversal.
+
+### --feedback--
+
+Think about the special function that converts an element into an index.
+
+---
+
+They use a hash function to compute a direct memory location for elements.
+
+---
+
+They always store a very small number of elements, making all operations fast.
+
+### --feedback--
+
+Think about the special function that converts an element into an index.
+
+## --video-solution--
+
+3
+
+## --text--
+
+In the context of hash maps and sets, what is a "hash collision"?
+
+## --answers--
+
+When an element is successfully found after a search.
+
+### --feedback--
+
+Think about the result when the hash function maps different inputs to the same output.
+
+---
+
+When an element is inserted at the very beginning of the collection.
+
+### --feedback--
+
+Think about the result when the hash function maps different inputs to the same output.
+
+---
+
+When the hash map runs out of memory and needs to resize.
+
+### --feedback--
+
+Think about the result when the hash function maps different inputs to the same output.
+
+---
+
+When two different keys or elements produce the same hash value.
+
+## --video-solution--
+
+4