mirror of
https://github.com/freeCodeCamp/freeCodeCamp.git
synced 2026-06-19 21:09:51 +08:00
feat(curriculum): add regex lecture transcripts (#57690)
This commit is contained in:
parent
fec4f62553
commit
69831b999a
@ -1,14 +1,140 @@
|
||||
---
|
||||
id: 6733aad43b3ebff588a26fb5
|
||||
title: What Are Regular Expressions, and What Are Some Common Methods?
|
||||
challengeType: 11
|
||||
videoId: nVAaxZ34khk
|
||||
challengeType: 19
|
||||
# videoId: nVAaxZ34khk
|
||||
dashedName: what-are-regular-expressions-and-what-are-some-common-methods
|
||||
---
|
||||
|
||||
# --description--
|
||||
|
||||
Watch the video lecture and answer the questions below.
|
||||
The video for this lecture isn't available yet, one will be available soon. Here is a transcript of the lecture for now:
|
||||
|
||||
Regular Expressions, or Regex, are a feature supported by many different programming languages.
|
||||
|
||||
A regular expression is a special syntax to create a "pattern", which you can then use to check against a string, extract text, and more.
|
||||
|
||||
Let's take a look at a basic Regular Expression:
|
||||
|
||||
```js
|
||||
const regex = /freeCodeCamp/;
|
||||
```
|
||||
|
||||
Notice how, in JavaScript, you define a regular expression by creating your pattern between two backslashes. Try not to confuse this with a comment, where the text comes after both backslashes.
|
||||
|
||||
This particular regular expression will match the text `freeCodeCamp`, with capital `C`'s, anywhere in a string. But how can you actually do that?
|
||||
|
||||
That brings us to our first method – the `.test()` method.
|
||||
|
||||
The `.test()` method is present on RegExp objects, which are objects representing a regular expression (such as the one we just defined).
|
||||
|
||||
The method accepts a string, which is the string to test for matches against the regular expression.
|
||||
|
||||
For example, let's try testing the string `e`.
|
||||
|
||||
```js
|
||||
const regex = /freeCodeCamp/;
|
||||
const test = regex.test("e");
|
||||
console.log(test);
|
||||
```
|
||||
|
||||
You can see we've called the `.test()` method on our new regex, and passed the string `e` as the argument. The result of the `test` variable is `false`. The `.test()` method returned `false` because the string `e` does not match the pattern `freeCodeCamp`. Even though the pattern `freeCodeCamp` includes the letter `e`, that's the opposite direction of how regular expressions work.
|
||||
|
||||
Let's take a look at a few more examples:
|
||||
|
||||
```js
|
||||
const regex = /freeCodeCamp/;
|
||||
console.log(regex.test("freeCodeCamp"));
|
||||
console.log(regex.test("freeCodeCamp is great"));
|
||||
console.log(regex.test("I love freeCodeCamp"));
|
||||
console.log(regex.test("freecodecamp"));
|
||||
console.log(regex.test("FREECODECAMP"));
|
||||
console.log(regex.test("free"));
|
||||
console.log(regex.test("code"));
|
||||
console.log(regex.test("camp"));
|
||||
```
|
||||
|
||||
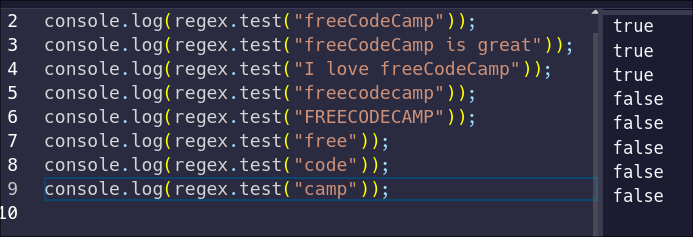
Take a moment to consider these. What do you think each line will print? Here's the result:
|
||||
|
||||
|
||||
|
||||
Did that surprise you?
|
||||
|
||||
Notice how the first three strings returned true. These strings all contain the text `freeCodeCamp` exactly, somewhere in the string.
|
||||
|
||||
The fifth and sixth tests return `false`. While they contain the text `freecodecamp`, the case does not match. Regular expressions are case-sensitive by default.
|
||||
|
||||
Finally, while the last three contain a portion of the pattern, the strings do not contain the entire pattern.
|
||||
|
||||
The `.test()` method returns a boolean, indicating whether the string matches the regular expression at all. But what if you wanted more information than that?
|
||||
|
||||
Well, strings have a `.match()` method. This method accepts a regular expression, although you can also pass a string which will be constructed into a regular expression. `Match` returns the match array for the string. What's a match array? Let's take a look:
|
||||
|
||||
```js
|
||||
const regex = /freeCodeCamp/;
|
||||
const match = "freeCodeCamp".match(regex);
|
||||
console.log(match);
|
||||
```
|
||||
|
||||
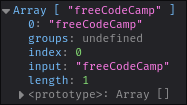
If we run this:
|
||||
|
||||
|
||||
|
||||
We get an array back! But it's a strange looking array. It's got some extra properties:
|
||||
|
||||
- The `groups` property would show any captured groups. You will learn what that means in a future lecture.
|
||||
|
||||
- The `index` property tells you at what character in the string the match was found. In our case, it was found at the beginning of the stream.
|
||||
|
||||
- The `input` property tells you the string the `.match()` method was called on.
|
||||
|
||||
Let's try a few more again, and see how the result changes:
|
||||
|
||||
```js
|
||||
const regex = /freeCodeCamp/;
|
||||
console.log("freeCodeCamp".match(regex));
|
||||
console.log("freeCodeCamp is great".match(regex));
|
||||
console.log("I love freeCodeCamp".match(regex));
|
||||
console.log("freecodecamp".match(regex));
|
||||
console.log("FREECODECAMP".match(regex));
|
||||
console.log("free".match(regex));
|
||||
```
|
||||
|
||||
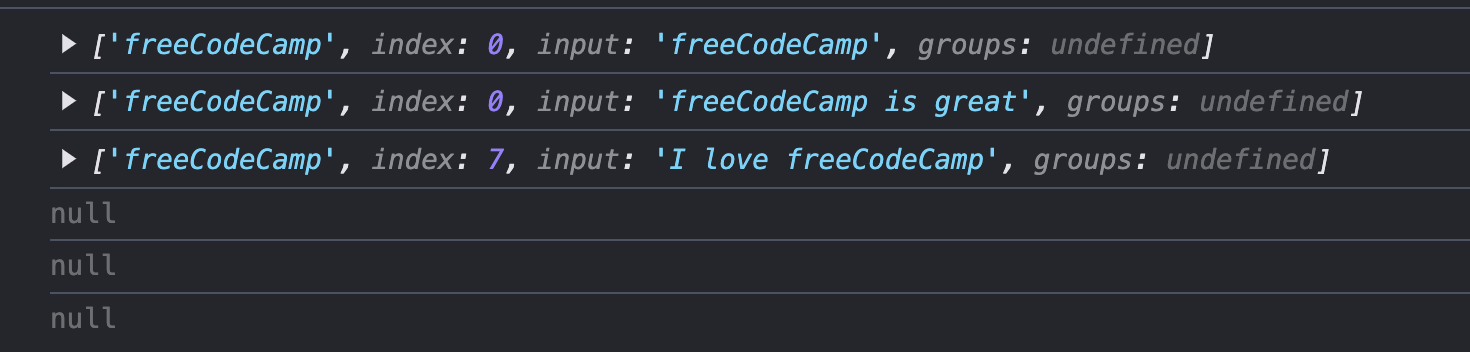
We know already that the first three strings should produce a match, so let's take a look at those:
|
||||
|
||||
|
||||
|
||||
Is that what you expected? You can see how the `input` and `index` have changed depending on the string provided, and the location of the match in the string.
|
||||
|
||||
The other three lines, which do not match, return `null` instead of an array.
|
||||
|
||||
Now that we can test and match strings with our regular expression, what if we want to replace the content of a string? Maybe someone has written `freecodecamp` in all lower case, and we want to automatically fix the casing for them.
|
||||
|
||||
First, we need to update our regular expression to match the lowercase form of `freecodecamp`, and create our test string:
|
||||
|
||||
```js
|
||||
const regex = /freecodecamp/;
|
||||
const str = "freecodecamp is rly kewl";
|
||||
```
|
||||
|
||||
Now, strings have a `replace` method which accepts two arguments: the regular expression to match (or a string, if you don't need all of the features of regex), and the string to replace the match with (or a function to run against each match).
|
||||
|
||||
So if we wanted to replace our `freecodecamp` with the proper casing:
|
||||
|
||||
```js
|
||||
const regex = /freecodecamp/;
|
||||
const str = "freecodecamp is rly kewl";
|
||||
const replaced = str.replace(regex, "freeCodeCamp");
|
||||
console.log(replaced);
|
||||
```
|
||||
|
||||
And we'll peek at the result:
|
||||
|
||||

|
||||
|
||||
You can see that `.replace()` returns the updated string, with the matching pattern replaced.
|
||||
|
||||
Regular expressions, and all of the methods associated with them, can seem complex and overwhelming. But you'll get the chance to explore them further in this next set of lectures.
|
||||
|
||||
# --questions--
|
||||
|
||||
|
||||
@ -1,14 +1,156 @@
|
||||
---
|
||||
id: 6733c5ba834ded4bb067e67c
|
||||
title: What Are Some Common Regular Expression Modifiers Used for Searching?
|
||||
challengeType: 11
|
||||
videoId: nVAaxZ34khk
|
||||
challengeType: 19
|
||||
# videoId: nVAaxZ34khk
|
||||
dashedName: what-are-some-common-regular-expression-modifiers-used-for-searching
|
||||
---
|
||||
|
||||
# --description--
|
||||
|
||||
Watch the lecture video and answer the questions below.
|
||||
The video for this lecture isn't available yet, one will be available soon. Here is a transcript of the lecture for now:
|
||||
|
||||
Let's learn about common regular expression modifiers.
|
||||
|
||||
Modifiers, often referred to as "flags", modify the behaviour of a regular expression. Let's recall our example from an earlier lecture:
|
||||
|
||||
```js
|
||||
const regex = /freeCodeCamp/;
|
||||
console.log(regex.test("freeCodeCamp"));
|
||||
console.log(regex.test("freeCodeCamp is great"));
|
||||
console.log(regex.test("I love freeCodeCamp"));
|
||||
console.log(regex.test("freecodecamp"));
|
||||
console.log(regex.test("FREECODECAMP"));
|
||||
console.log(regex.test("free"));
|
||||
console.log(regex.test("code"));
|
||||
console.log(regex.test("camp"));
|
||||
```
|
||||
|
||||
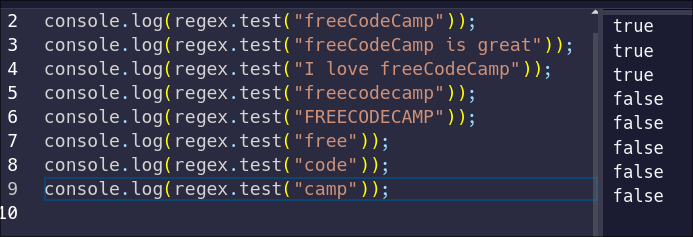
If you remember, the all-lowercase and all-uppercase `freecodecamp` strings failed to match the pattern:
|
||||
|
||||
|
||||
|
||||
This is because, by default, regular expressions are case-sensitive. But what if we could tell the regular expression to be case-insensitive?
|
||||
|
||||
Well, there's a modifier for that. The `i` flag makes a regex ignore case. How can we use it? Flags go after the closing backslash in a regular expression.
|
||||
|
||||
```js
|
||||
const regex = /freeCodeCamp/i;
|
||||
console.log(regex.test("freeCodeCamp"));
|
||||
console.log(regex.test("freeCodeCamp is great"));
|
||||
console.log(regex.test("I love freeCodeCamp"));
|
||||
console.log(regex.test("freecodecamp"));
|
||||
console.log(regex.test("FREECODECAMP"));
|
||||
console.log(regex.test("free"));
|
||||
console.log(regex.test("code"));
|
||||
console.log(regex.test("camp"));
|
||||
```
|
||||
|
||||
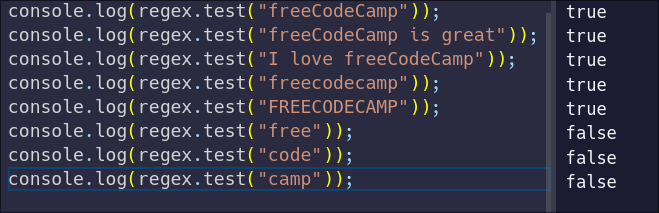
Notice the change to the regular expression on the first line. Now we can check how this changes things:
|
||||
|
||||
|
||||
|
||||
Because our regular expression is now case-insensitive, the all-lowercase and all-uppercase strings have "passed" the test. This can also work for a string with a random mix of uppercase and lowercase letters:
|
||||
|
||||

|
||||
|
||||
There are quite a few other flags that you can use. The `g` flag, or global modifier, allows your regular expression to match a pattern more than once.
|
||||
|
||||
Let's see how that affects our code. You'll notice we kept the `i` flag – a regular expression can use multiple flags (as many as needed) to achieve your desired behavior.
|
||||
|
||||
```js
|
||||
const regex = /freeCodeCamp/gi;
|
||||
console.log(regex.test("freeCodeCamp"));
|
||||
console.log(regex.test("freeCodeCamp is great"));
|
||||
console.log(regex.test("I love freeCodeCamp"));
|
||||
console.log(regex.test("freecodecamp"));
|
||||
console.log(regex.test("FREECODECAMP"));
|
||||
console.log(regex.test("free"));
|
||||
console.log(regex.test("code"));
|
||||
console.log(regex.test("camp"));
|
||||
```
|
||||
|
||||
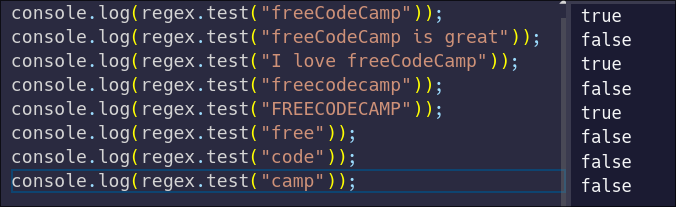
Wait a second… what's this? It would seem that the global modifier is making some of our strings that should be passing fail instead. Why?
|
||||
|
||||
|
||||
|
||||
Well, the global modifier makes your regular expression stateful. This means it keeps track of where it has previously matched a pattern. So when it matches the first `freeCodeCamp` string, it remembers that it found a match starting at index 0.
|
||||
|
||||
We then test it against `freeCodeCamp is great`, but it doesn't start at index 0. The regular expression "knows" it found a match at index 0 already, so even though this is a different string it starts from the end index of the match.
|
||||
|
||||
`freeCodeCamp` is 12 characters long, so a match at 0 ends at index 11. The matching will resume at index 12. And since ` is great` does not match `freeCodeCamp`, it returns `false`.
|
||||
|
||||
Then, because it fails to find a match, it "loses" its state and starts the following match back at 0. If we switch our logs around so that a string with the match at 0 is followed immediately by a string that has a match later than index 11:
|
||||
|
||||

|
||||
|
||||
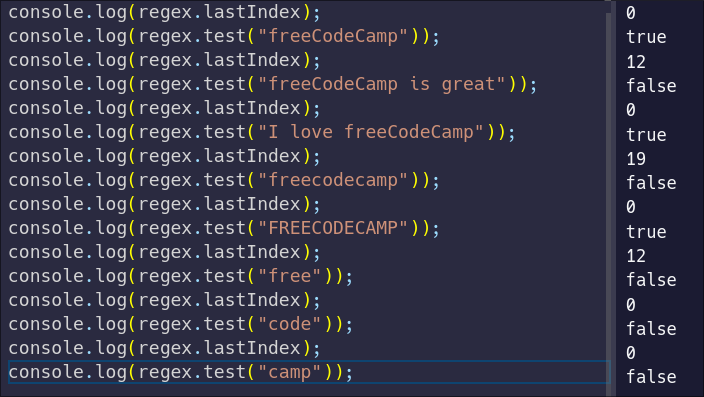
When a regular expression is global, it gets a new property called `lastIndex`. Grabbing our previous code, let's see how this property works:
|
||||
|
||||
|
||||
|
||||
Looking at this example, you can see how the state of the regular expression changes with each `test` call, using the `lastIndex` to track its previous matches.
|
||||
|
||||
The global flag is great when you need to get multiple matches from a single string, but if you're testing multiple strings with the same regular expression it's best to leave the `g` flag off.
|
||||
|
||||
Before learning about the next flag, you need to learn about anchors.
|
||||
|
||||
The `^` anchor, at the beginning of the regular expression, says "match the start of the string".
|
||||
|
||||
The `$` anchor, at the end of the regular expression, says "match the end of the string".
|
||||
|
||||
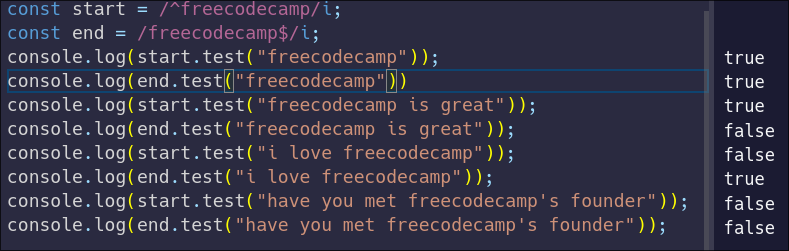
Let's see what that looks like:
|
||||
|
||||
|
||||
|
||||
Take a moment to compare the outputs on the right. See how the start anchor only matches at the beginning of the string, and the end anchor only matches at the end of the string.
|
||||
|
||||
But what about matching across multiple lines? Let's take a look at that:
|
||||
|
||||
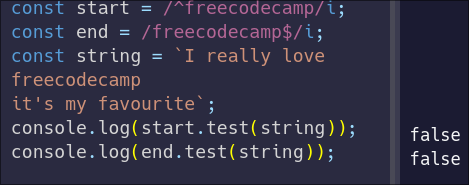
|
||||
|
||||
Even though `freecodecamp` is in there, on its own line, it fails both tests. This is because, by default, anchors look for the beginning and end of the entire string. But you can make a regex handle multiple lines with the m flag, or the multi-line modifier.
|
||||
|
||||
Let's add that to our regular expressions to see what we get:
|
||||
|
||||
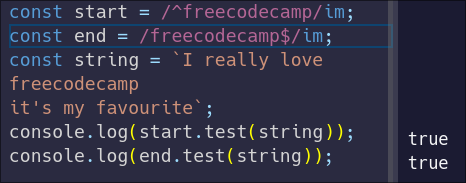
|
||||
|
||||
Now they both match! Because the freecodecamp is entirely on its own line, the start anchor matches the beginning of that line, and the end anchor matches the end of that line.
|
||||
|
||||
Finally, you have the `d` flag, or indices modifier. Remember that the `i` flag is for case-insensitivity, so the indices modifier needed a different flag. The `d` flag expands the information you get in a match object. Let's add it to our regular expression.
|
||||
|
||||
```js
|
||||
const regex = /freecodecamp/di;
|
||||
const string = "we love freecodecamp isn't freecodecamp great?";
|
||||
console.log(string.match(regex));
|
||||
```
|
||||
|
||||
And the result is…
|
||||
|
||||
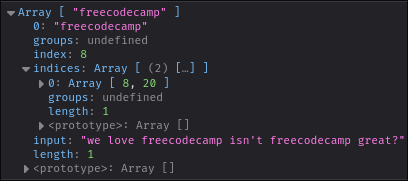
|
||||
|
||||
Our match object gets a new `indices` property!
|
||||
|
||||
This property is an array of two numbers – the first being the index in the original string where the match starts, and the second being the index after the match ended. This array also has an extra `groups` property, which is also for named capture groups.
|
||||
|
||||
There are a few other flags that you should know are available to you, but are less common in typical code.
|
||||
|
||||
The first is the unicode modifier, or `u` flag. This expands the functionality of a regular expression to allow it to match special unicode characters.
|
||||
|
||||
You'll learn more about character classes in a later lecture, but the `u` flag gives you access to special classes like `Extended_Pictographic` to match most emoji.
|
||||
|
||||
There is also a `v` flag, which further expands the functionality of the unicode matching.
|
||||
|
||||
The second is the sticky modifier, or the `y` flag. The sticky modifier behaves very similarly to the global modifier, but with a few exceptions.
|
||||
|
||||
The biggest one is that a global regular expression will start from `lastIndex` and search the entire remainder of the string for another match, but a sticky regular expression will return `null` and reset the `lastIndex` to 0 if there is not immediately a match at the previous `lastIndex`.
|
||||
|
||||
And the last is the single-line modifier, or the `s` flag.
|
||||
|
||||
Remember that the multiline modifier allows start and end anchors to match the start and end of a line, instead of the entire string.
|
||||
|
||||
The single-line modifier allows a wildcard character, represented by a `.` in regex, to match linebreaks – effectively treating the string as a single line of text.
|
||||
|
||||
There are quite a few of these modifiers, but the `i` and `g` flags are the ones you'll use most frequently, and are the most important to remember.
|
||||
|
||||
# --questions--
|
||||
|
||||
|
||||
@ -1,14 +1,139 @@
|
||||
---
|
||||
id: 6733c5c549775c4be710237c
|
||||
title: How Can You Match and Replace All Occurrences in a String?
|
||||
challengeType: 11
|
||||
videoId: nVAaxZ34khk
|
||||
challengeType: 19
|
||||
# videoId: nVAaxZ34khk
|
||||
dashedName: how-can-you-match-and-replace-all-occurrences-in-a-string
|
||||
---
|
||||
|
||||
# --description--
|
||||
|
||||
Watch the lecture video and answer the questions below.
|
||||
The video for this lecture isn't available yet, one will be available soon. Here is a transcript of the lecture for now:
|
||||
|
||||
Let's learn how to match or replace all occurrences of a pattern in a string.
|
||||
|
||||
You have previously learned about the `replace` and `match` methods, as well as the global `g` modifier. Now you can combine that knowledge to handle all patterns in a string.
|
||||
|
||||
Let's recall our original `match` code.
|
||||
|
||||
```js
|
||||
const regex = /freeCodeCamp/;
|
||||
const match = "freeCodeCamp".match(regex);
|
||||
console.log(match);
|
||||
```
|
||||
|
||||
And our resulting `match` object:
|
||||
|
||||
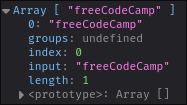
|
||||
|
||||
But what if we have a string with multiple occurrences of `freecodecamp` to match? Let's take a look at how `match` behaves with that. We'll throw in our old replace example too, just to compare.
|
||||
|
||||
```js
|
||||
const regex = /freecodecamp/;
|
||||
const str = "freecodecamp is the best we love freecodecamp";
|
||||
const matched = str.match(regex);
|
||||
const replaced = str.replace(regex, "freeCodeCamp");
|
||||
console.log(matched);
|
||||
console.log(replaced);
|
||||
```
|
||||
|
||||
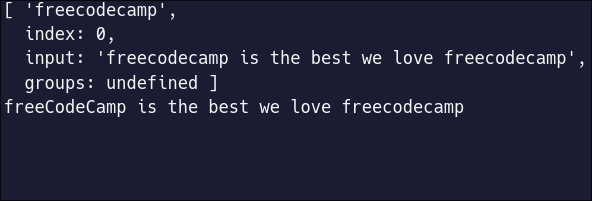
And the result:
|
||||
|
||||
|
||||
|
||||
Oh no! `Match` only returned the first match, and `replace` only replaced the first match. This is because, by default, `match` and `replace` only operate against the first pattern occurrence.
|
||||
|
||||
Thankfully, you can avoid this by using the global modifier on your regular expression. Let's add that to ours:
|
||||
|
||||
```js
|
||||
const regex = /freecodecamp/g;
|
||||
const str = "freecodecamp is the best we love freecodecamp";
|
||||
const matched = str.match(regex);
|
||||
const replaced = str.replace(regex, "freeCodeCamp");
|
||||
console.log(matched);
|
||||
console.log(replaced);
|
||||
```
|
||||
|
||||
And confirm the result:
|
||||
|
||||

|
||||
|
||||
That worked! Our `replace` call replaced all of the lowercase `freecodecamp` strings, and our `match` method matched both of them.
|
||||
|
||||
What's interesting here is that when you use the global modifier with match, you lose the extra information about capture groups and string indicies that would come in the `match` array.
|
||||
|
||||
Thankfully, 2019's ECMAScript update brought us two new methods: `matchAll` and `replaceAll`.
|
||||
|
||||
Like their singular counterparts, these methods accept a string or regular expression, and `replaceAll` also accepts a second argument as the string to replace with. But unlike the previous methods, `replaceAll` and `matchAll` will throw an error if you give them a regular expression without the global modifier.
|
||||
|
||||
Let's update our code to use these new methods:
|
||||
|
||||
```js
|
||||
const pattern = "freecodecamp";
|
||||
const str = "freecodecamp is the best we love freecodecamp";
|
||||
const matched = str.matchAll(pattern);
|
||||
const replaced = str.replaceAll(pattern, "freeCodeCamp");
|
||||
console.log(matched);
|
||||
console.log(replaced);
|
||||
```
|
||||
|
||||
And our result:
|
||||
|
||||

|
||||
|
||||
Good news! Our `replaceAll` worked exactly as we wanted – it replaced all occurrences of the lowercased `freecodecamp` with the properly camelCased version. But what is that empty object?
|
||||
|
||||
Well, `matchAll` returns a special type of object called an Iterator, which the freeCodeCamp console isn't prepared to handle. If we peek in our browser console:
|
||||
|
||||
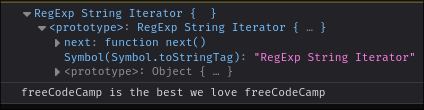
|
||||
|
||||
The Iterator has a `next` method, which we can call to get the next value. Let's go ahead and call `matched.next()`, and log the result:
|
||||
|
||||
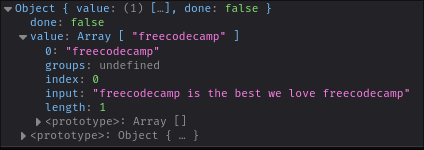
|
||||
|
||||
There's our match array! `.next()` gives us an object with two values: done, which is false when there are more elements available in the iterator, and value which is the value we just iterated over.
|
||||
|
||||
So, if we call it one more time:
|
||||
|
||||
```js
|
||||
const regex = /freecodecamp/g;
|
||||
const str = "freecodecamp is the best we love freecodecamp";
|
||||
const matched = str.matchAll(regex);
|
||||
const replaced = str.replaceAll(regex, "freeCodeCamp");
|
||||
console.log(matched);
|
||||
console.log(replaced);
|
||||
console.log(matched.next());
|
||||
console.log(matched.next());
|
||||
```
|
||||
|
||||
Wait, why does it say done is still `false`? There should only be two matches in the array, right?
|
||||
|
||||
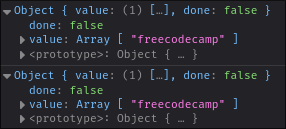
|
||||
|
||||
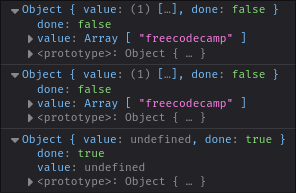
Let's call it a third time and see what we get:
|
||||
|
||||
|
||||
|
||||
`done` is finally `true`, but why is that value `undefined`? Well, as it turns out, the `matchAll` iterator is lazy. It doesn't find all of your matches at once. It only finds a match when you tell it to by calling `next()`.
|
||||
|
||||
As long as it finds a match, it isn't "done". Once it fails to find a match and brings back `undefined`, it is "done". This may seem inconvenient, but it can be quite helpful when your regular expression is computationally expensive.
|
||||
|
||||
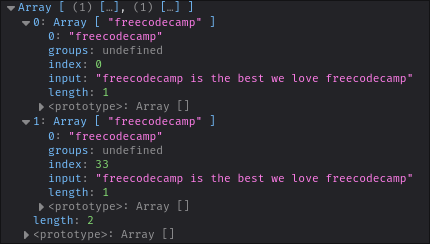
If your example is less so, like ours, you can skip that feature and extract all of the matches at once by converting it to an array. This is achieved by calling `Array.from()` and passing your iterator as the argument.
|
||||
|
||||
Let's update our code to use that – we'll go ahead and clean up our replaceAll calls since we know that works.
|
||||
|
||||
```js
|
||||
const regex = /freecodecamp/g;
|
||||
const str = "freecodecamp is the best we love freecodecamp";
|
||||
const matched = str.matchAll(regex);
|
||||
console.log(Array.from(matched))
|
||||
```
|
||||
|
||||
And we finally get our array of matches:
|
||||
|
||||
|
||||
|
||||
These powerful methods can help you manipulate and extract data from strings without having to sacrifice performance or readability.
|
||||
|
||||
# --questions--
|
||||
|
||||
|
||||
@ -1,14 +1,120 @@
|
||||
---
|
||||
id: 6733c5d0048bb74c18431296
|
||||
title: What Are Character Classes, and What Are Some Common Examples?
|
||||
challengeType: 11
|
||||
videoId: nVAaxZ34khk
|
||||
challengeType: 19
|
||||
# videoId: nVAaxZ34khk
|
||||
dashedName: what-are-character-classes-and-what-are-some-common-examples
|
||||
---
|
||||
|
||||
# --description--
|
||||
|
||||
Watch the lecture video and answer the questions below.
|
||||
The video for this lecture isn't available yet, one will be available soon. Here is a transcript of the lecture for now:
|
||||
|
||||
Let's learn about character classes in regular expressions, including some common examples.
|
||||
|
||||
Character classes are a special syntax you can use to match sets or subsets of characters.
|
||||
|
||||
The first character class you should learn is the wild card class.
|
||||
|
||||
The wild card is represented by a period or dot (`.`), and matches any single character except line breaks. To allow the wildcard class to match line breaks, remember that you would need to use the `s` flag.
|
||||
|
||||
A regular expression that matched the letter `A` followed by one single character might look like:
|
||||
|
||||
```js
|
||||
const regex = /a./;
|
||||
```
|
||||
|
||||
This can be helpful when you are looking for specific patterns in a string, but don't know what might be between those two patterns. But you can also use character classes to narrow down your matches.
|
||||
|
||||
For example, what if you wanted to match a numerical character? You might have to write out every possible digit, separating them with the `|` or operator:
|
||||
|
||||
```js
|
||||
const regex = /0|1|2|3|4|5|6|7|8|9/;
|
||||
```
|
||||
|
||||
A character class exists for this exact pattern, and gives you a shorthand syntax for writing the same thing. In this case, the character class is written as a backslash (`\`)followed by a `d` character:
|
||||
|
||||
```js
|
||||
const regex = /\d/;
|
||||
```
|
||||
|
||||
This regular expression will match the exact same pattern as our previous expression: a single numerical character anywhere in the string.
|
||||
|
||||
Now consider a regular expression which also needs to match any letter character `a` through `z`. You could write out each individual character separated by the or operator. Or you could use another character class.
|
||||
|
||||
The `\w` class, which is a backslash followed by a `w`, represents any word character.
|
||||
|
||||
```js
|
||||
const regex = /\w/;
|
||||
```
|
||||
|
||||
A word character is defined as any letter, from `a` to `z`, or a number from `0` to `9`, or the underscore (`_`) character.
|
||||
|
||||
The inclusion of the underscore might seem strange, but consider the naming conventions for variables – variable names can often include underscores, so `\w` is designed to match that as well.
|
||||
|
||||
There is one more special character class to consider: the white-space class `\s`, represented by a backslash followed by an `s`. This character class will match any white space, including new lines, spaces, tabs, and special unicode space characters.
|
||||
|
||||
These special character classes can be negated. To negate one of these character classes, instead of using a lowercase letter after the backslash, use the uppercase equivalent.
|
||||
|
||||
```js
|
||||
const regex = /\D/;
|
||||
```
|
||||
|
||||
This regular expression, for example, does not match a numerical character. Instead, it matches any single character that is not a numerical character.
|
||||
|
||||
Negating the `\w` class would match any character that is not `a` to `z`, `0` to `9`, or an underscore, and negating the `\s` character class would match any character that is not a white-space.
|
||||
|
||||
But what if you wanted to match more specific subsets of characters?
|
||||
|
||||
Maybe you're a professor grading papers, and you need to make sure your grades are valid. A valid grade can be `A`, `B`, `C`, `D`, or `F`. You can use square brackets to construct your own character class:
|
||||
|
||||
```js
|
||||
const regex = /[abcdf]/;
|
||||
```
|
||||
|
||||
This regular expression will match a single character that is in the list "`a`, `b`, `c`, `d`, or `f`".
|
||||
|
||||
What about checking only grades that pass? A passing grade would be an `A`, `B`, `C`, or `D`. You can modify your character class to stop matching "`f`" by removing that character from the list:
|
||||
|
||||
```js
|
||||
const regex = /[abcd]/;
|
||||
```
|
||||
|
||||
You may have noticed now that our character class consists only of consecutive characters. `A`, `B`, `C`, and `D` are all directly next to each other in the alphabet. For numbers, consecutive characters might be `4`, `5`, and `6`.
|
||||
|
||||
When you have consecutive characters, you can create a range using the hyphen character.
|
||||
|
||||
Using a range, we can turn our regular expression into a shorter syntax while matching the exact same pattern.
|
||||
|
||||
```js
|
||||
const regex = /[a-d]/;
|
||||
```
|
||||
|
||||
Remember that regular expressions are case-sensitive by default. This means our character class will only match the lowercase variants of `a`, `b`, `c`, and `d`. You could use the `i` flag to achieve this, but you can also bake it directly into your character class by including the uppercase variants:
|
||||
|
||||
```js
|
||||
const regex = /[a-zA-Z]/;
|
||||
```
|
||||
|
||||
You can also mix digits and numbers in your character class. For example, if you wanted the behavior of the `\w` class without the underscore, you could construct your own:
|
||||
|
||||
```js
|
||||
const regex = /[a-zA-Z0-9]/;
|
||||
```
|
||||
|
||||
Note that if you want your character class to match a literal hyphen, you need to place a hyphen at the beginning or end of the class.
|
||||
|
||||
```js
|
||||
const regex = /[-a-zA-Z0-9]/;
|
||||
```
|
||||
|
||||
And finally, you can include special character classes in your custom class. Maybe you want to include a hyphen in the set matched by `\w`:
|
||||
|
||||
```js
|
||||
const regex = /[-\w]/;
|
||||
```
|
||||
|
||||
Character classes are a powerful tool that gives you incredible control over your pattern matching.
|
||||
|
||||
# --questions--
|
||||
|
||||
|
||||
@ -1,14 +1,76 @@
|
||||
---
|
||||
id: 6733c5dc74176e4c496d09e6
|
||||
title: What Are Lookaheads and Lookbehind Assertions, and How Do They Work?
|
||||
challengeType: 11
|
||||
videoId: nVAaxZ34khk
|
||||
challengeType: 19
|
||||
# videoId: nVAaxZ34khk
|
||||
dashedName: what-are-lookaheads-and-lookbehind-assertions-and-how-do-they-work
|
||||
---
|
||||
|
||||
# --description--
|
||||
|
||||
Watch the lecture video and answer the questions below.
|
||||
The video for this lecture isn't available yet, one will be available soon. Here is a transcript of the lecture for now:
|
||||
|
||||
Let's learn about lookahead and lookbehind assertions in regular expressions.
|
||||
|
||||
Lookahead and lookbehind assertions allow you to match specific patterns based on the presence or lack of surrounding patterns. There are four variations of these assertions.
|
||||
|
||||
First is the positive lookahead assertion. This assertion will match a pattern when the pattern is followed by another pattern.
|
||||
|
||||
To construct a positive lookahead, you need to start with the pattern you want to match. Then, use parentheses to wrap the pattern you want to use as your condition. After the opening parenthesis, use `?=` to define that pattern as a positive lookahead.
|
||||
|
||||
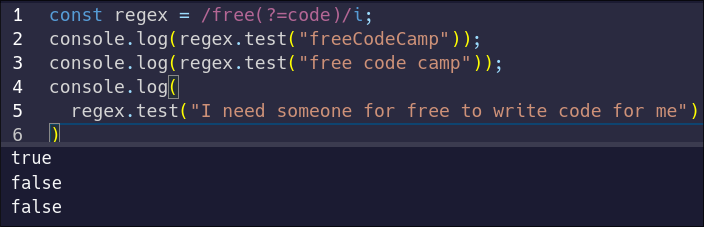
This pattern will only match the word `free` if it is followed by `code`.
|
||||
|
||||
```js
|
||||
const regex = /free(?=code)/i;
|
||||
```
|
||||
|
||||
Let's test the behavior of our pattern:
|
||||
|
||||
|
||||
|
||||
Notice how only the string where `free` is immediately followed by `code` passes the test.
|
||||
|
||||
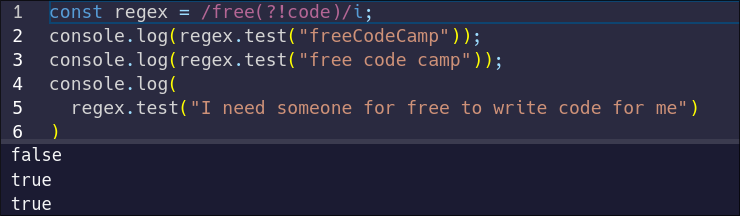
But what if you want to match the presence of `free` when it is NOT followed by `code`? You can turn your positive lookahead into a negative lookahead, to invert the behavior. To do this, change your `?=` to `?!`:
|
||||
|
||||
```js
|
||||
const regex = /free(?!code)/i;
|
||||
```
|
||||
|
||||
Let's test this against our same strings:
|
||||
|
||||
|
||||
|
||||
As expected, the results are reversed. The only string that fails is the first string, where `free` is immediately followed by `code`.
|
||||
|
||||
Lookbehind assertions function similarly to lookahead assertions, except that instead of matching conditionally based on a following pattern, they match conditionally based on a preceding pattern. Let's take a look at a positive lookbehind.
|
||||
|
||||
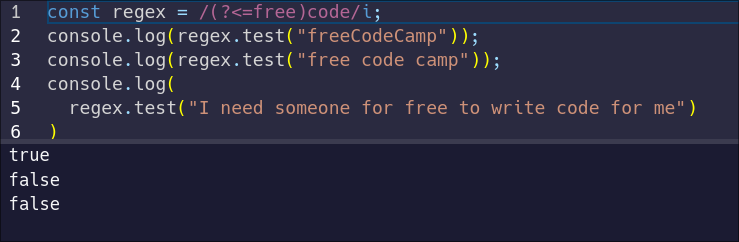
A positive lookbehind is denoted with `?<=` instead of `?=`. Let's make our regular expression match `code` when it is preceded by `free`:
|
||||
|
||||
```js
|
||||
const regex = /(?<=free)code/i;
|
||||
```
|
||||
|
||||
Just like with our positive lookahead, our positive lookbehind matches the first string because `code` is immediately preceded by `free`.
|
||||
|
||||
|
||||
|
||||
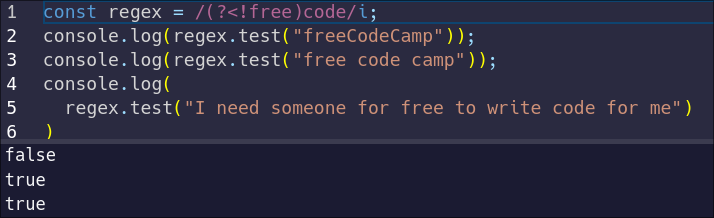
To match `code` when it is NOT preceded by `free`, we can use a negative lookbehind. A negative lookbehind is defined by replacing `?<=` with `?<!`:
|
||||
|
||||
```js
|
||||
const regex = /(?<!free)code/i;
|
||||
```
|
||||
|
||||
This would match any occurrence of `code` that is NOT immediately preceded by `free`.
|
||||
|
||||
|
||||
|
||||
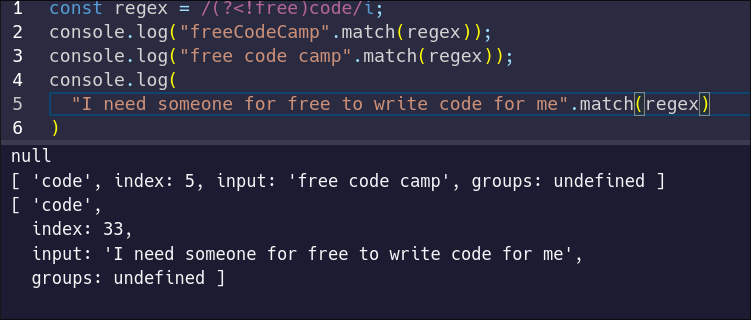
Remember that `Regex.prototype.test` only confirms whether a string matches the regular expression. Let's use our negative lookbehind with `String.prototype.match` to see how assertions affect that:
|
||||
|
||||
|
||||
|
||||
Notice how even though our regular expression uses a lookbehind to check for the presence of free, it does not match free. The only text included in the match is code.
|
||||
|
||||
Lookaheads and lookbehinds are incredibly useful for conditionally matching text without impacting the returned value of your match.
|
||||
|
||||
# --questions--
|
||||
|
||||
|
||||
@ -1,14 +1,104 @@
|
||||
---
|
||||
id: 6733c5e54e3a154c8078ed48
|
||||
title: What Are Regex Quantifiers, and How Do They Work?
|
||||
challengeType: 11
|
||||
videoId: nVAaxZ34khk
|
||||
challengeType: 19
|
||||
# videoId: nVAaxZ34khk
|
||||
dashedName: what-are-regex-quantifiers-and-how-do-they-work
|
||||
---
|
||||
|
||||
# --description--
|
||||
|
||||
Watch the lecture video and answer the questions below.
|
||||
The video for this lecture isn't available yet, one will be available soon. Here is a transcript of the lecture for now:
|
||||
|
||||
Let's learn about quantifiers in regular expressions.
|
||||
|
||||
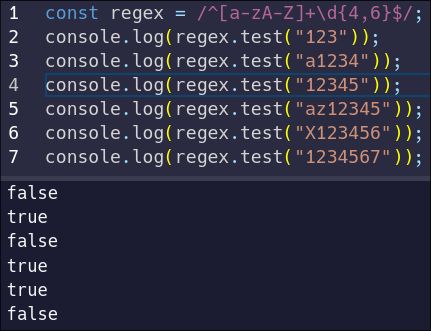
Consider a scenario where you want to match a four-digit identification code. You know you can use the `\d` character class, so you might write that four times. And to avoid any extraneous characters, you'd include both the start and end anchors.
|
||||
|
||||
```js
|
||||
const regex = /^\d\d\d\d$/;
|
||||
```
|
||||
|
||||
And this does work – it will match four numerical characters. But rather than having to write out the same class multiple times, you can give it a quantifier.
|
||||
|
||||
Quantifiers are defined by curly braces containing one or two numbers. Let's use a quantifier in our pattern:
|
||||
|
||||
```js
|
||||
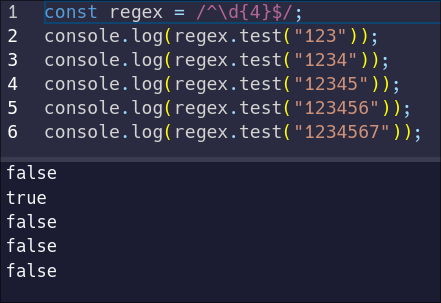
const regex = /^\d{4}$/;
|
||||
```
|
||||
|
||||
Notice how our quantifier contains only the number `4`. This syntax means "match the previous character exactly four times". Let's see how that behaves:
|
||||
|
||||
|
||||
|
||||
The pattern only matches the string with exactly four digits, because we have used the anchors and our quantifier only allows exactly four digits. But maybe the identification code only needs to be a minimum of four digits.
|
||||
|
||||
To allow for four or more digits, add a comma after the number in your quantifier:
|
||||
|
||||
```js
|
||||
const regex = /^\d{4,}$/;
|
||||
```
|
||||
|
||||
Now, our syntax allows the pattern to match four or more digits. Let's test it:
|
||||
|
||||
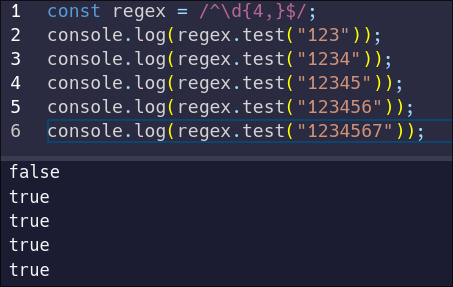
|
||||
|
||||
A seven-digit identifier is rather long. These identifiers should have a maximum of 6 digits, and a minimum of 4 digits. To achieve this, you can add a second number to your quantifier after the comma.
|
||||
|
||||
```js
|
||||
const regex = /^\d{4,6}$/;
|
||||
```
|
||||
|
||||
And now our pattern no longer matches the seven-digit identifier, because it is greater than our six-digit maximum.
|
||||
|
||||
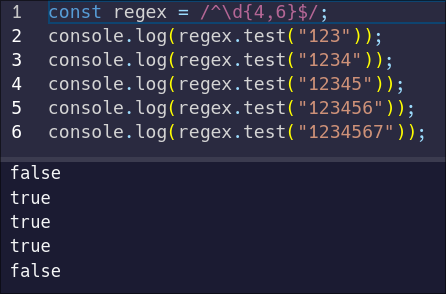
|
||||
|
||||
Note that you cannot use this syntax to set a maximum alone – you must always set a minimum. But if you set the minimum to `1`, you can effectively achieve the same result.
|
||||
|
||||
We've received updated requirements from our users. Identifiers can now optionally start with a letter. We already know the character class for this, so let's add that to our regular expression.
|
||||
|
||||
```js
|
||||
const regex = /^[a-zA-z]\d{4,6}$/;
|
||||
```
|
||||
|
||||
But now we mandate the presence of a letter. How can we make it optional?
|
||||
|
||||
You could use the quantifier syntax with `0` as the minimum and `1` as the maximum:
|
||||
|
||||
```js
|
||||
const regex = /^[a-zA-Z]{0,1}\d{4,6}$/;
|
||||
```
|
||||
|
||||
But there's actually a special shorthand quantifier for a single optional character – the question mark. Let's replace our quantifier with the question mark:
|
||||
|
||||
```js
|
||||
const regex = /^[a-zA-Z]?\d{4,6}$/;
|
||||
```
|
||||
|
||||
We should validate the result:
|
||||
|
||||
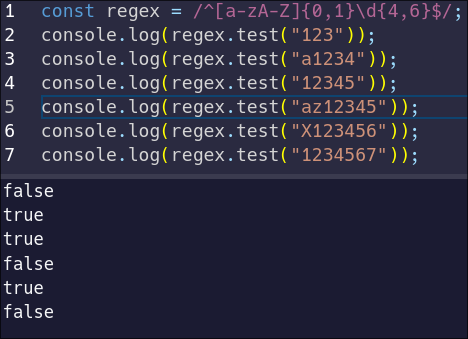
|
||||
|
||||
Our pattern now allows for a single optional letter, followed by four to six digits.
|
||||
|
||||
Unfortunately, we've just realized we read the requirements wrong. We need to allow for any number of letters before the numbers. We can use our quantifier with a `0` minimum and no defined maximum:
|
||||
|
||||
```js
|
||||
const regex = /^[a-zA-Z]{0,}\d{4,6}$/;
|
||||
```
|
||||
|
||||
But our pattern is getting long again. Thankfully, there's another short-hand for "match the previous character zero or more times" – the asterisk symbol. Let's replace our quantifier with that in the pattern, and test it:
|
||||
|
||||
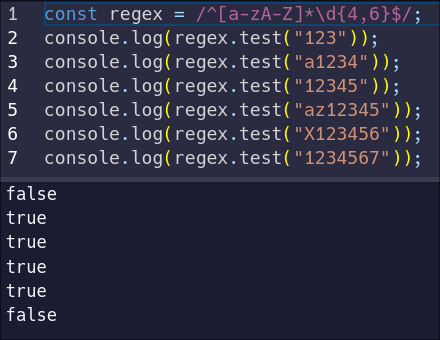
|
||||
|
||||
Now we successfully match any identifier with zero or more letters followed by four to six numbers. But it turns out this is crashing our system – we actually have to require at least one letter.
|
||||
|
||||
Again, we could use a quantifier with a minimum of one and no defined maximum, or we could use yet another special syntax – the plus symbol:
|
||||
|
||||
|
||||
|
||||
Now the identifiers that do not start with at least one letter fail, regardless of how many numbers there are.
|
||||
|
||||
You can use quantifiers to greatly enhance the brevity and readability of your regular expressions.
|
||||
|
||||
# --questions--
|
||||
|
||||
|
||||
@ -1,14 +1,123 @@
|
||||
---
|
||||
id: 6733c5f20cc9584cada942a4
|
||||
title: What Are Capturing Groups and Backreferences, and How Do They Work?
|
||||
challengeType: 11
|
||||
videoId: nVAaxZ34khk
|
||||
challengeType: 19
|
||||
# videoId: nVAaxZ34khk
|
||||
dashedName: what-are-capturing-groups-and-backreferences-and-how-do-they-work
|
||||
---
|
||||
|
||||
# --description--
|
||||
|
||||
Watch the lecture video and answer the questions below.
|
||||
The video for this lecture isn't available yet, one will be available soon. Here is a transcript of the lecture for now:
|
||||
|
||||
Let's learn about capturing groups and back references in regular expressions.
|
||||
|
||||
A capturing group allows you to "capture" a portion of the matched string to use however you might need. Capturing groups are defined by parentheses containing the pattern to capture, with no leading characters like a lookahead.
|
||||
|
||||
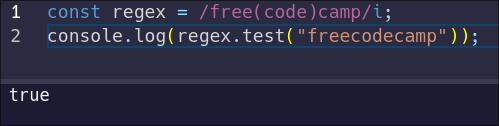
Let's capture the `code` from our `freeCodeCamp` regular expression. To do that, we'll enclose `code` in parentheses and define it as a capture group.
|
||||
|
||||
```js
|
||||
const regex = /free(code)camp/i;
|
||||
```
|
||||
|
||||
To confirm the behavior, we can test it against a `freecodecamp` string:
|
||||
|
||||
|
||||
|
||||
But this doesn't actually make use of our captured group. Instead, let's take a look at the result of using `match`:
|
||||
|
||||
```js
|
||||
const regex = /free(code)camp/i;
|
||||
console.log("freecodecamp".match(regex));
|
||||
```
|
||||
|
||||
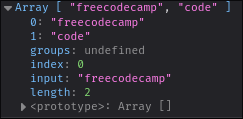
Here we can see that our `match` array has a second element, which is the portion of the string which was captured by our capture group.
|
||||
|
||||
Notice how the capture group matches the exact pattern `code`, where a character class would match a single character from the list `c`, `o`, `d`, and `e`.
|
||||
|
||||
|
||||
|
||||
But how can we actually use this? Well, capture groups are often used when replacing contents of a string. Let's set up some code to do that. We're going to turn `freecodecamp` into `paidcodeworld`.
|
||||
|
||||
```js
|
||||
const regex = /free(code)camp/i;
|
||||
console.log("freecodecamp".replace(regex, "paidcodeworld"));
|
||||
```
|
||||
|
||||
This works on its own, but what if we didn't know how many `o`'s were in "`code`"? If we need a quantifier for one or more `o`'s…
|
||||
|
||||
```js
|
||||
const regex = /free(co+de)camp/i;
|
||||
console.log("freecoooooooodecamp".replace(regex, "paidcodeworld"));
|
||||
```
|
||||
|
||||
We're getting `paidcodeworld` as our result. We want to preserve the number of `o`'s, so we need to reuse what was captured by the regular expression.
|
||||
|
||||
This is where a backreference comes in. Instead of hardcoding the "`code`" portion of our replacement string, we can reference the captured group directly.
|
||||
|
||||
In a replace call, you achieve a backreference by using a dollar sign (`$`) followed by the number of the capture group to use.
|
||||
|
||||
In our case, that would be `$1`, since code is captured in the first capture group.
|
||||
|
||||

|
||||
|
||||
We have now successfully preserved an unknown number of `o` characters when converting `freecodecamp` into `paidcodeworld`. But backreferences aren't just limited to the replace call. You can actually use them directly in a regular expression.
|
||||
|
||||
This would allow you to match a previously captured pattern later on in the regular expression.
|
||||
|
||||
Let's say we want to match `freecodecamp` twice, with the same number of `o`'s, but anywhere in the string.
|
||||
|
||||
First, we need to separate them with our wildcard character, and allow any number of characters to match that wildcard:
|
||||
|
||||
```js
|
||||
const regex = /free(co+de)camp.*free(co+de)camp/i;
|
||||
```
|
||||
|
||||
This current expression won't ensure that the number of `o` characters is the same, however. To achieve that, we need to replace the second capture group with a reference to the first.
|
||||
|
||||
Inside a regular expression, a backreference is denoted with a backslash followed by the number of the capture group:
|
||||
|
||||

|
||||
|
||||
And with that, we can see that a string with the correct number of `o`'s matches, while a string with two different numbers of `o`'s does not.
|
||||
|
||||
This syntax is great, but can quickly get confusing when you are referencing multiple capture groups. Thankfully, instead of using numbers, you can give your groups names.
|
||||
|
||||
To define a named capture group, you add a question mark (`?`) followed by the name enclosed in less than and greater than signs to the beginning of the group. Let's name our capture group "`code`":
|
||||
|
||||
```js
|
||||
const regex = /free(?<code>co+de)camp.*free\1camp/i;
|
||||
```
|
||||
|
||||
Now we can update our backreference in the regular expression to refer to this group. A named back reference starts with a backslash followed by the letter `k` in JavaScript. Then you add the name, again enclosed in less than and greater than signs. Let's take a look at that:
|
||||
|
||||
```js
|
||||
const regex = /free(?<code>co+de)camp.*free\k<code>camp/i;
|
||||
```
|
||||
|
||||
Now if we check our `test` call, we can see that we still pass:
|
||||
|
||||

|
||||
|
||||
To use our named capture group in a `replace` call, we'd insert a dollar sign into the string, followed by the name enclosed in less than and greater than signs:
|
||||
|
||||

|
||||
|
||||
Finally, sometimes you want to create a group of characters, but don't need the captured result.
|
||||
|
||||
Let's say we want to match either `freecodecamp` or `freecandycamp`. You could create two patterns separated by an OR assertion:
|
||||
|
||||
```js
|
||||
const regex = /freecodecamp|freecandycamp/i;
|
||||
```
|
||||
|
||||
But this can become quite lengthy for larger-scale regular expressions. Instead, you can create a non-capturing group around the characters that you need to OR:
|
||||
|
||||
```js
|
||||
const regex = /free(?:code|candy)camp/i;
|
||||
```
|
||||
|
||||
A non-capturing group does not store the `code|candy` match separately in memory. You can't backreference a non-capturing group. But it can be helpful for creating alternate patterns without sacrificing readability or performance.
|
||||
|
||||
# --questions--
|
||||
|
||||
|
||||
Loading…
Reference in New Issue
Block a user