diff --git a/README.md b/README.md
index 560246c4..5c9cb0fa 100644
--- a/README.md
+++ b/README.md
@@ -17,7 +17,7 @@ ScrapeGraphAI is a *web scraping* python library that uses LLM and direct graph
Just say which information you want to extract and the library will do it for you!
-  +
+ 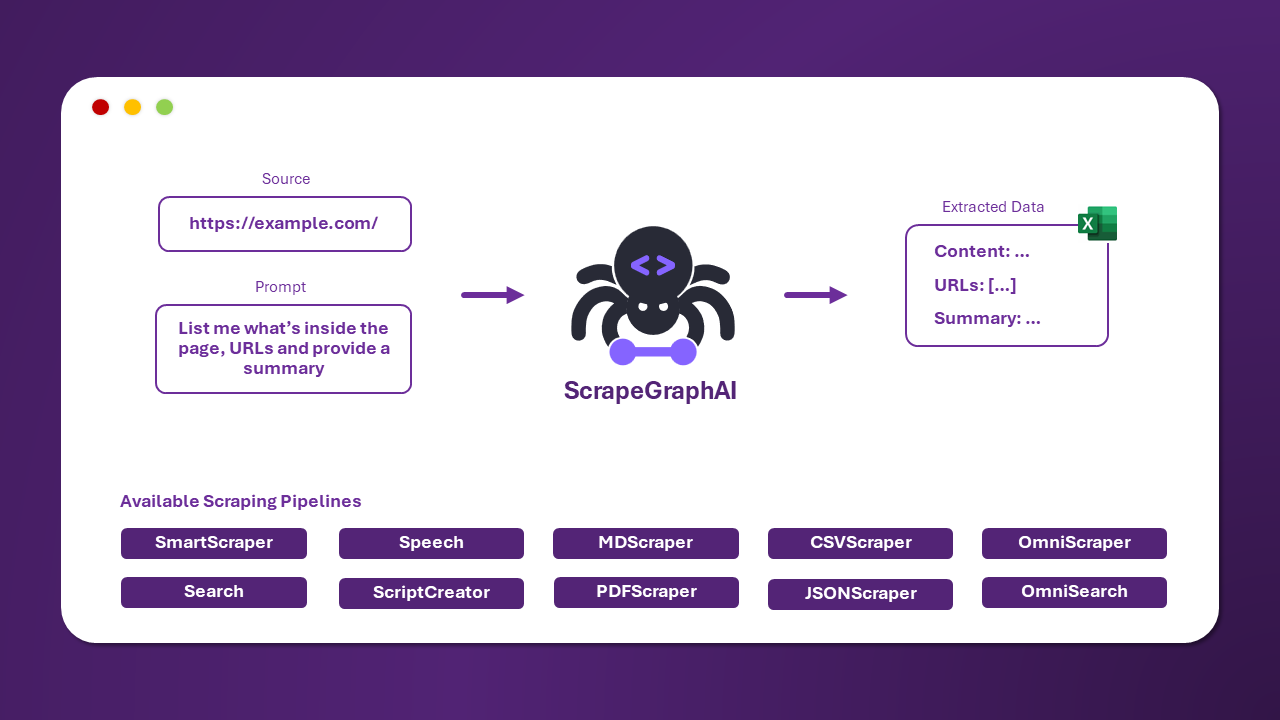
## 🚀 Quick install
@@ -26,10 +26,69 @@ The reference page for Scrapegraph-ai is available on the official page of PyPI:
```bash
pip install scrapegraphai
+
+playwright install
```
**Note**: it is recommended to install the library in a virtual environment to avoid conflicts with other libraries 🐱
+## 💻 Usage
+There are multiple standard scraping pipelines that can be used to extract information from a website (or local file).
+
+The most common one is the `SmartScraperGraph`, which extracts information from a single page given a user prompt and a source URL.
+
+
+```python
+import json
+from scrapegraphai.graphs import SmartScraperGraph
+
+# Define the configuration for the scraping pipeline
+graph_config = {
+ "llm": {
+ "api_key": "YOUR_OPENAI_APIKEY",
+ "model": "gpt-4o-mini",
+ },
+ "verbose": True,
+ "headless": False,
+}
+
+# Create the SmartScraperGraph instance
+smart_scraper_graph = SmartScraperGraph(
+ prompt="Find some information about what does the company do, the name and a contact email.",
+ source="https://scrapegraphai.com/",
+ config=graph_config
+)
+
+# Run the pipeline
+result = smart_scraper_graph.run()
+print(json.dumps(result, indent=4))
+```
+
+The output will be a dictionary like the following:
+
+```python
+{
+ "company": "ScrapeGraphAI",
+ "name": "ScrapeGraphAI Extracting content from websites and local documents using LLM",
+ "contact_email": "contact@scrapegraphai.com"
+}
+```
+
+There are other pipelines that can be used to extract information from multiple pages, generate Python scripts, or even generate audio files.
+
+| Pipeline Name | Description |
+|-------------------------|------------------------------------------------------------------------------------------------------------------|
+| SmartScraperGraph | Single-page scraper that only needs a user prompt and an input source. |
+| SearchGraph | Multi-page scraper that extracts information from the top n search results of a search engine. |
+| SpeechGraph | Single-page scraper that extracts information from a website and generates an audio file. |
+| ScriptCreatorGraph | Single-page scraper that extracts information from a website and generates a Python script. |
+| SmartScraperMultiGraph | Multi-page scraper that extracts information from multiple pages given a single prompt and a list of sources. |
+| ScriptCreatorMultiGraph | Multi-page scraper that generates a Python script for extracting information from multiple pages and sources. |
+
+It is possible to use different LLM through APIs, such as **OpenAI**, **Groq**, **Azure** and **Gemini**, or local models using **Ollama**.
+
+Remember to have [Ollama](https://ollama.com/) installed and download the models using the **ollama pull** command, if you want to use local models.
+
## 🔍 Demo
Official streamlit demo:
@@ -45,140 +104,6 @@ The documentation for ScrapeGraphAI can be found [here](https://scrapegraph-ai.r
Check out also the Docusaurus [here](https://scrapegraph-doc.onrender.com/).
-## 💻 Usage
-There are multiple standard scraping pipelines that can be used to extract information from a website (or local file):
-- `SmartScraperGraph`: single-page scraper that only needs a user prompt and an input source;
-- `SearchGraph`: multi-page scraper that extracts information from the top n search results of a search engine;
-- `SpeechGraph`: single-page scraper that extracts information from a website and generates an audio file.
-- `ScriptCreatorGraph`: single-page scraper that extracts information from a website and generates a Python script.
-
-- `SmartScraperMultiGraph`: multi-page scraper that extracts information from multiple pages given a single prompt and a list of sources;
-- `ScriptCreatorMultiGraph`: multi-page scraper that generates a Python script for extracting information from multiple pages given a single prompt and a list of sources.
-
-It is possible to use different LLM through APIs, such as **OpenAI**, **Groq**, **Azure** and **Gemini**, or local models using **Ollama**.
-
-### Case 1: SmartScraper using Local Models
-
-Remember to have [Ollama](https://ollama.com/) installed and download the models using the **ollama pull** command.
-
-```python
-from scrapegraphai.graphs import SmartScraperGraph
-
-graph_config = {
- "llm": {
- "model": "ollama/mistral",
- "temperature": 0,
- "format": "json", # Ollama needs the format to be specified explicitly
- "base_url": "http://localhost:11434", # set Ollama URL
- },
- "embeddings": {
- "model": "ollama/nomic-embed-text",
- "base_url": "http://localhost:11434", # set Ollama URL
- },
- "verbose": True,
-}
-
-smart_scraper_graph = SmartScraperGraph(
- prompt="List me all the projects with their descriptions",
- # also accepts a string with the already downloaded HTML code
- source="https://perinim.github.io/projects",
- config=graph_config
-)
-
-result = smart_scraper_graph.run()
-print(result)
-
-```
-
-The output will be a list of projects with their descriptions like the following:
-
-```python
-{'projects': [{'title': 'Rotary Pendulum RL', 'description': 'Open Source project aimed at controlling a real life rotary pendulum using RL algorithms'}, {'title': 'DQN Implementation from scratch', 'description': 'Developed a Deep Q-Network algorithm to train a simple and double pendulum'}, ...]}
-```
-
-### Case 2: SearchGraph using Mixed Models
-
-We use **Groq** for the LLM and **Ollama** for the embeddings.
-
-```python
-from scrapegraphai.graphs import SearchGraph
-
-# Define the configuration for the graph
-graph_config = {
- "llm": {
- "model": "groq/gemma-7b-it",
- "api_key": "GROQ_API_KEY",
- "temperature": 0
- },
- "embeddings": {
- "model": "ollama/nomic-embed-text",
- "base_url": "http://localhost:11434", # set ollama URL arbitrarily
- },
- "max_results": 5,
-}
-
-# Create the SearchGraph instance
-search_graph = SearchGraph(
- prompt="List me all the traditional recipes from Chioggia",
- config=graph_config
-)
-
-# Run the graph
-result = search_graph.run()
-print(result)
-```
-
-The output will be a list of recipes like the following:
-
-```python
-{'recipes': [{'name': 'Sarde in Saòre'}, {'name': 'Bigoli in salsa'}, {'name': 'Seppie in umido'}, {'name': 'Moleche frite'}, {'name': 'Risotto alla pescatora'}, {'name': 'Broeto'}, {'name': 'Bibarasse in Cassopipa'}, {'name': 'Risi e bisi'}, {'name': 'Smegiassa Ciosota'}]}
-```
-### Case 3: SpeechGraph using OpenAI
-
-You just need to pass the OpenAI API key and the model name.
-
-```python
-from scrapegraphai.graphs import SpeechGraph
-
-graph_config = {
- "llm": {
- "api_key": "OPENAI_API_KEY",
- "model": "gpt-3.5-turbo",
- },
- "tts_model": {
- "api_key": "OPENAI_API_KEY",
- "model": "tts-1",
- "voice": "alloy"
- },
- "output_path": "audio_summary.mp3",
-}
-
-# ************************************************
-# Create the SpeechGraph instance and run it
-# ************************************************
-
-speech_graph = SpeechGraph(
- prompt="Make a detailed audio summary of the projects.",
- source="https://perinim.github.io/projects/",
- config=graph_config,
-)
-
-result = speech_graph.run()
-print(result)
-
-```
-
-The output will be an audio file with the summary of the projects on the page.
-
-## Sponsors
-
## 🤝 Contributing
 -
-