diff --git a/README.md b/README.md
index 3da2d3ce..d2a57877 100644
--- a/README.md
+++ b/README.md
@@ -24,9 +24,21 @@ Just say which information you want to extract and the library will do it for yo
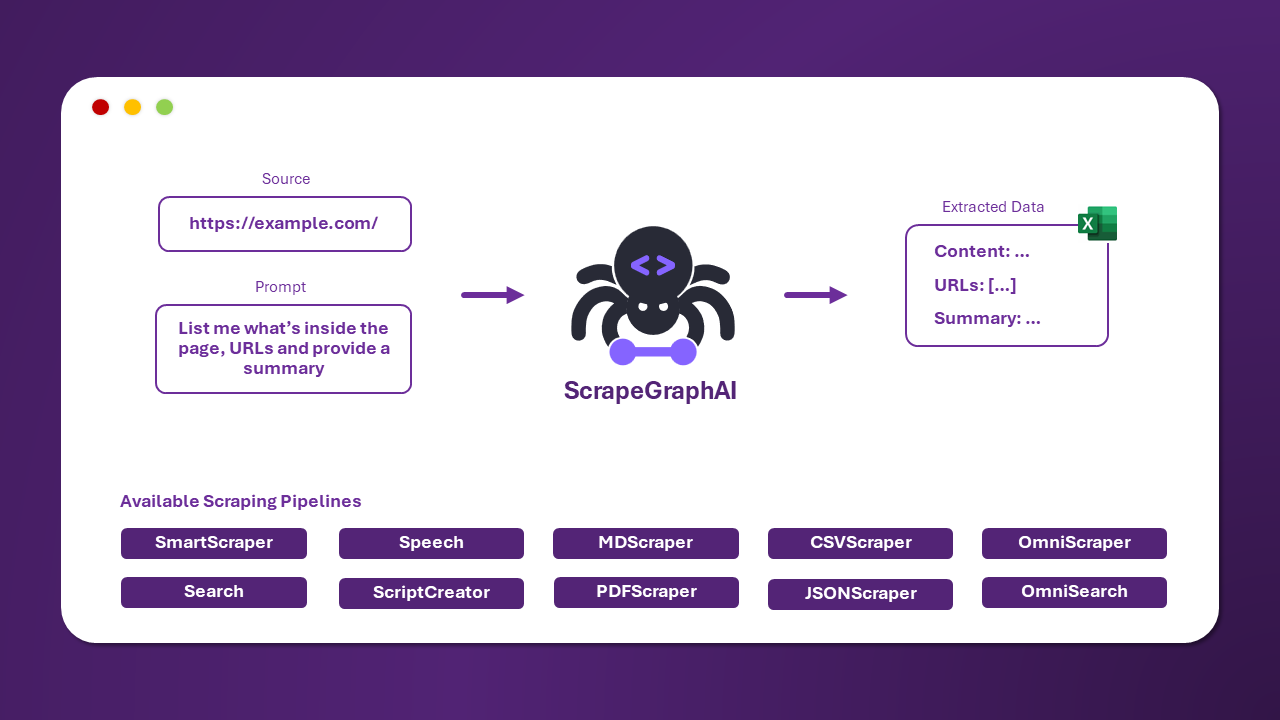 -## News 📰
+## 🔗 ScrapeGraph API & SDKs
+If you are looking for a quick solution to integrate ScrapeGraph in your system, check out our powerful API [here!](https://dashboard.scrapegraphai.com/login)
-- ScrapegraphAI has now his APIs! Check it out [here](https://scrapegraphai.com)!
+
-## News 📰
+## 🔗 ScrapeGraph API & SDKs
+If you are looking for a quick solution to integrate ScrapeGraph in your system, check out our powerful API [here!](https://dashboard.scrapegraphai.com/login)
-- ScrapegraphAI has now his APIs! Check it out [here](https://scrapegraphai.com)!
+
+  +
+
+
+We offer SDKs in both Python and Node.js, making it easy to integrate into your projects. Check them out below:
+
+| SDK | Language | GitHub Link |
+|-----------|----------|-----------------------------------------------------------------------------|
+| Python SDK | Python | [scrapegraph-py](https://github.com/ScrapeGraphAI/scrapegraph-sdk/tree/main/scrapegraph-py) |
+| Node.js SDK | Node.js | [scrapegraph-js](https://github.com/ScrapeGraphAI/scrapegraph-sdk/tree/main/scrapegraph-js) |
+
+The Official API Documentation can be found [here](https://docs.scrapegraphai.com/).
## 🚀 Quick install
@@ -87,8 +99,8 @@ graph_config = {
# Create the SmartScraperGraph instance
smart_scraper_graph = SmartScraperGraph(
- prompt="Find some information about what does the company do, the name and a contact email.",
- source="https://scrapegraphai.com/",
+ prompt="Extract me all the news from the website",
+ source="https://www.wired.com",
config=graph_config
)
@@ -100,10 +112,20 @@ print(json.dumps(result, indent=4))
The output will be a dictionary like the following:
```python
-{
- "company": "ScrapeGraphAI",
- "name": "ScrapeGraphAI Extracting content from websites and local documents using LLM",
- "contact_email": "contact@scrapegraphai.com"
+"result": {
+ "news": [
+ {
+ "title": "The New Jersey Drone Mystery May Not Actually Be That Mysterious",
+ "link": "https://www.wired.com/story/new-jersey-drone-mystery-maybe-not-drones/",
+ "author": "Lily Hay Newman"
+ },
+ {
+ "title": "Former ByteDance Intern Accused of Sabotage Among Winners of Prestigious AI Award",
+ "link": "https://www.wired.com/story/bytedance-intern-best-paper-neurips/",
+ "author": "Louise Matsakis"
+ },
+ ...
+ ]
}
```
There are other pipelines that can be used to extract information from multiple pages, generate Python scripts, or even generate audio files.
@@ -135,8 +157,7 @@ Try it directly on the web using Google Colab:
## 📖 Documentation
The documentation for ScrapeGraphAI can be found [here](https://scrapegraph-ai.readthedocs.io/en/latest/).
-
-Check out also the Docusaurus [here](https://scrapegraph-doc.onrender.com/).
+Check out also the Docusaurus [here](https://docs-oss.scrapegraphai.com/).
## 🏆 Sponsors
@@ -204,4 +225,4 @@ ScrapeGraphAI is licensed under the MIT License. See the [LICENSE](https://githu
- We would like to thank all the contributors to the project and the open-source community for their support.
- ScrapeGraphAI is meant to be used for data exploration and research purposes only. We are not responsible for any misuse of the library.
-Made with ❤️ by [ScrapeGraph AI](https://scrapegraphai.com)
+Made with ❤️ by [ScrapeGraph AI](https://scrapegraphai.com)
\ No newline at end of file
diff --git a/docs/assets/api-banner.png b/docs/assets/api-banner.png
new file mode 100644
index 00000000..06de517d
Binary files /dev/null and b/docs/assets/api-banner.png differ